

【AWS】サーバレスの便利さがイメージできないので実際にLambda関数を作成してみた
目次[非表示]
- 1.はじめに
- 2.サーバレスってそもそも何?
- 3.Lambdaってそもそも何?
- 4.実際に作成する
- 5.実行ロールの選択
- 6.ネットワークの有効化
- 7.トリガーの追加
- 8.送信先の追加
- 9.出来上がったLambda関数を実行してログを確認してみる。
- 10.今回つまずいたところ
- 11.まとめ
- 12.出典・参考資料
はじめに
こんにちは。株式会社divxのエンジニア佐藤です。
最近AWSの学習をし始めたのですが、「サーバレス」というワードを目にする機会が多いです。
その名の通り「サーバーを意識することなく開発できる」というサービスでして、とても便利…ということは学習をしていて字面上では理解しているのですが、実際にどれほど便利なものなのかは正直イメージできていません。
なので今回は、実際にAWSマネジメントコンソール上で手を動かしつつ、噂の便利さを体験してみたいと思います。
サーバレスってそもそも何?
まずはそもそもサーバレスって何?という話から。
先ほども書いた通り「サーバレス」という名前ですが本当にサーバーがないわけではなく、「サーバーの存在を意識せずに利用できる」というのが特徴ですね。
サーバーの管理が不要なので、利用する側は開発に専念することができ、従量課金なのでコストを抑えることができるなどのメリットがあります。
AWSで言うとLambda、Dynamo DB、Aurora Serverless、SQS、SNSなどがサーバレスサービスですね。
参考:https://aws.amazon.com/jp/serverless/
こんな感じでAWSのサーバレスサービスはいくつかあるのですが、今回はその中でも代表的な「Lambda」を使ってみたいと思います。
SAAの学習をしていて、「S3にオブジェクトが作成されたのをトリガーにLambdaを起動してDynamoDBにメタデータを保存うんぬん。。。」みたいな作りがコスパも良くて疎結合でとても良い♫みたいな文章を何度も見たので。
「何度も見た」イコール「めちゃ大事」ということだと思うので、白羽の矢を立てました。
Lambdaってそもそも何?
そもそもLambdaって何?って方もいるかと思うので、特徴を以下に列挙しておきますね。
- サーバーの存在を意識することなくコードが実行できる。
- 実行基盤が全てAWS側で管理されているマネージド型サービス。
- リクエストの数とコードの実行時間に基づいて課金される。
- 1ヶ月100万件の無料リクエスト枠がある。
- タイムアウト時間はデフォルトで3秒、最大値は15分。
- 同時実行は最大1000。
「サーバーの存在を意識することなくコードが実行できる」というのは先ほども書きましたが、そのほかにも「1ヶ月100万件の無料リクエスト」「リクエストの数とコードの実行時間に基づいて課金」など、コスパの面でもメリットが大きいですね。
参考
https://aws.amazon.com/jp/lambda/
https://aws.amazon.com/jp/lambda/features/
https://aws.amazon.com/jp/lambda/pricing/
https://aws.amazon.com/jp/lambda/faqs/
実際に作成する
それではここから実際に手を動かしつつLambdaの便利さを体感していきたいと思います。
早速マネジメントコンソールにログインしていきます。
検索窓からLambdaを選択すると、以下の画面になります。
続いてサイドバーの中にある「関数」をクリック。
以下の画面になります。
右上に表示されている「関数の作成」ボタンを押すと、以下の画面に遷移します。
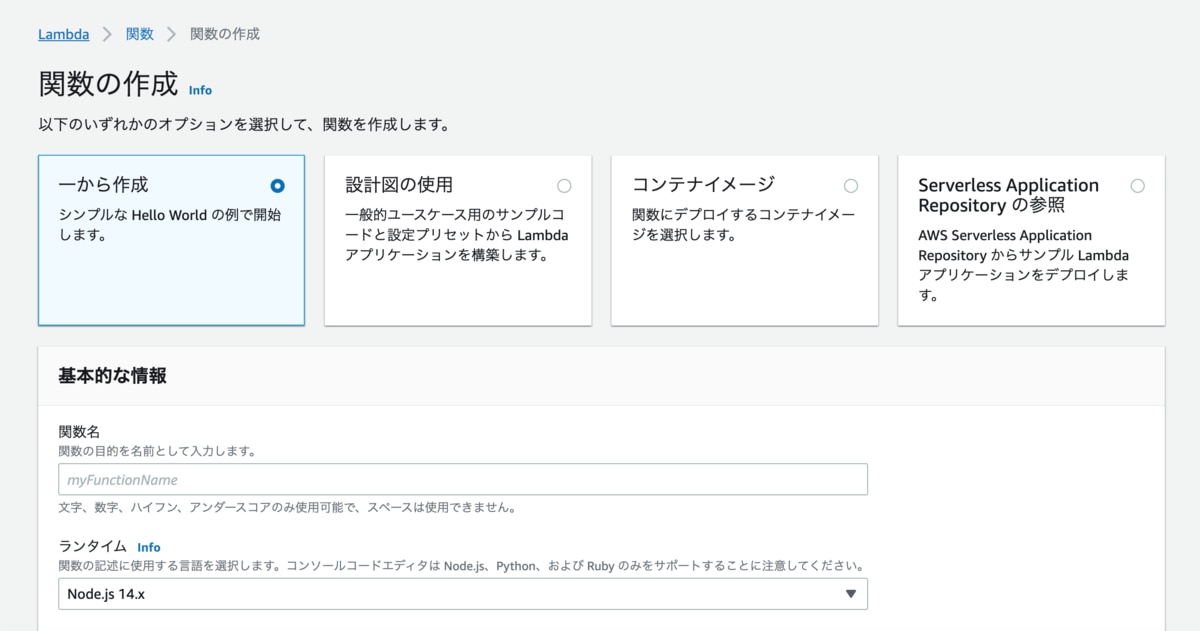
関数作成のオプションが4種類ありますね。
- 一から作成
- 設計図の使用
- コンテナイメージ
- Serverless Application Repositoryの参照
1から自分で作成することもできますし、AWSや第三者が作成した関数をテンプレとして利用することも可能。よく使うものはテンプレに用意されているので、こちらを使って作成した方が簡単ですね。
今回は「一から作成」を選んで進めていきます。
画面を下にスクロールすると「基本的な情報」を入力する欄があるので、関数名、言語などを入力していきます。
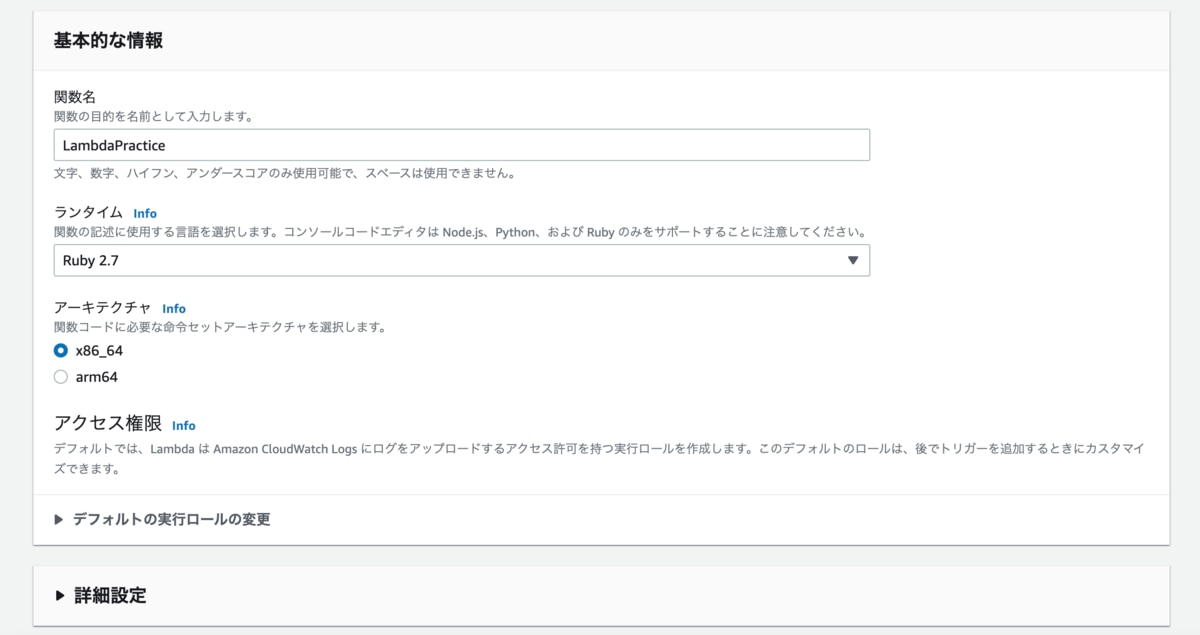
こんな感じで関数名は「LambdaPractice」、ランタイム(言語)は「Ruby」を選択しました。
その他にも「実行ロールの選択」や「コード署名の有効化」「ネットワークの有効化」なども選択可能になっています。
実行ロールの選択
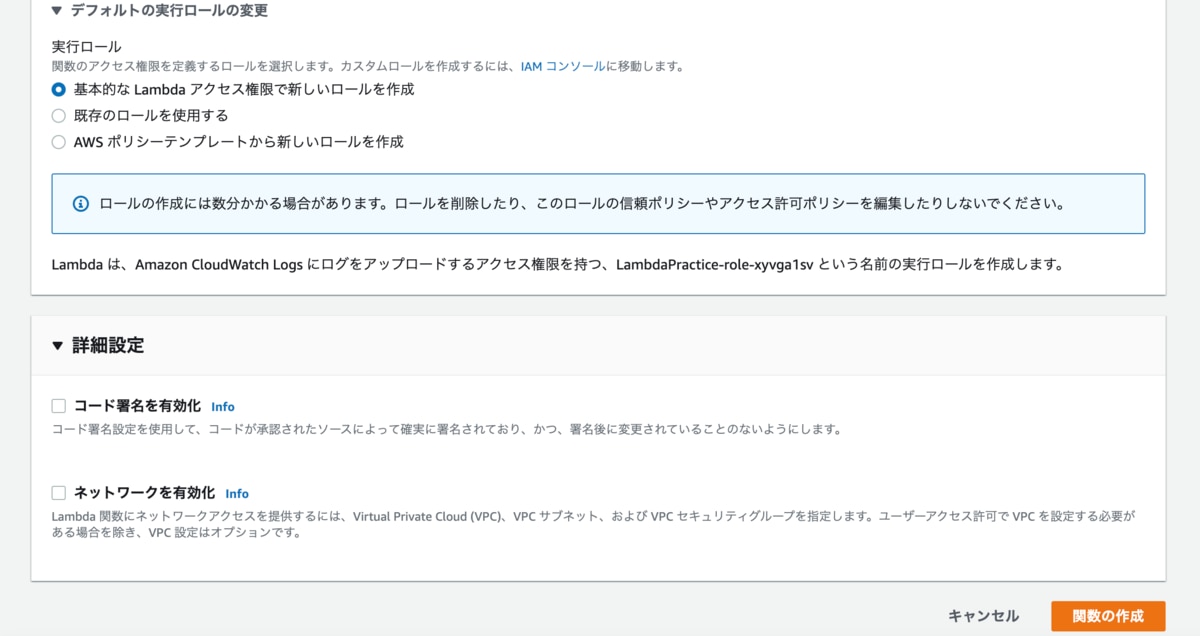
実行ロールというのは関数のアクセス権限を定義するものです。
説明文にある通り、デフォルトだと「CloudWatch Logs」にログをアップロードする権限をもつロールが自動で作成されるとのこと。
作成済みのロールを使用することもできますし、テンプレートから選択することも可能ですね。
今回はデフォルトのまま進めていきます。
ネットワークの有効化
ネットワークを有効化すると、VPCを指定してLambda関数を作成することが可能です。
何も指定しないとAWSが管理するネットワーク内に作成されるのですが、ここで指定することで既に存在している任意のVPC内にLambda関数を配置できるわけですね。
今回は特に指定せずに進めていきたいと思います。
一番下「関数を作成」ボタンを押下すると以下の画面になります。
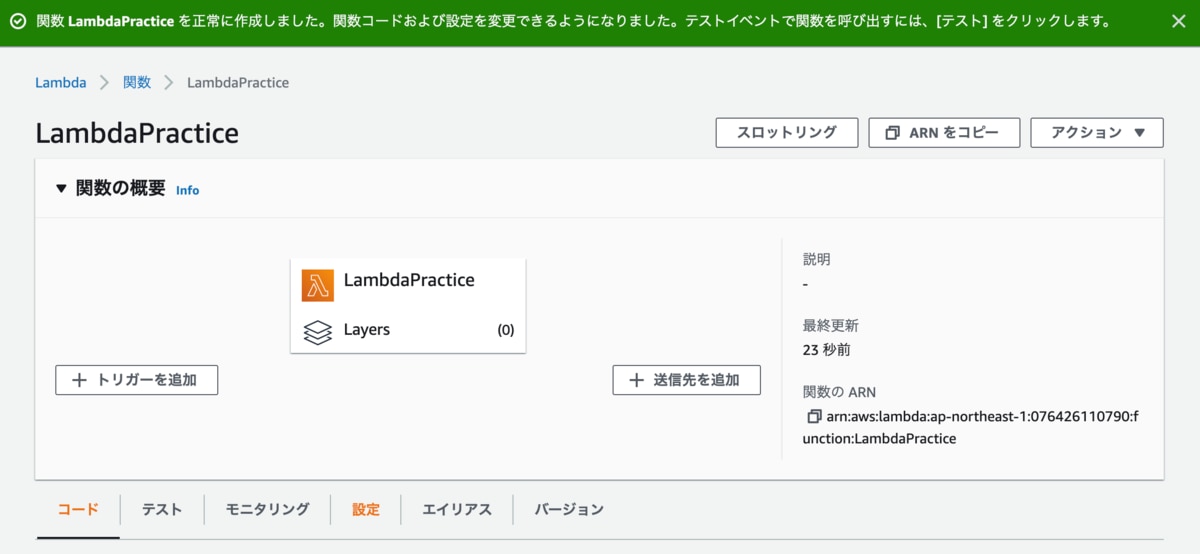
こんな感じで、無事に「LambdaPractice」という名前のLambda関数が作成されました。
こちらの画面からトリガーや送信先を追加、テストの実行やその他の設定などができるようになっています。
ここでちょっと横道に逸れますが、先ほどデフォルトだと「CloudWatch Logsにログをアップロードする権限をもつロールが自動で作成される」との説明があったので、実際に作成されたロールを確認していきます。
IAMから確認すると以下の通り。
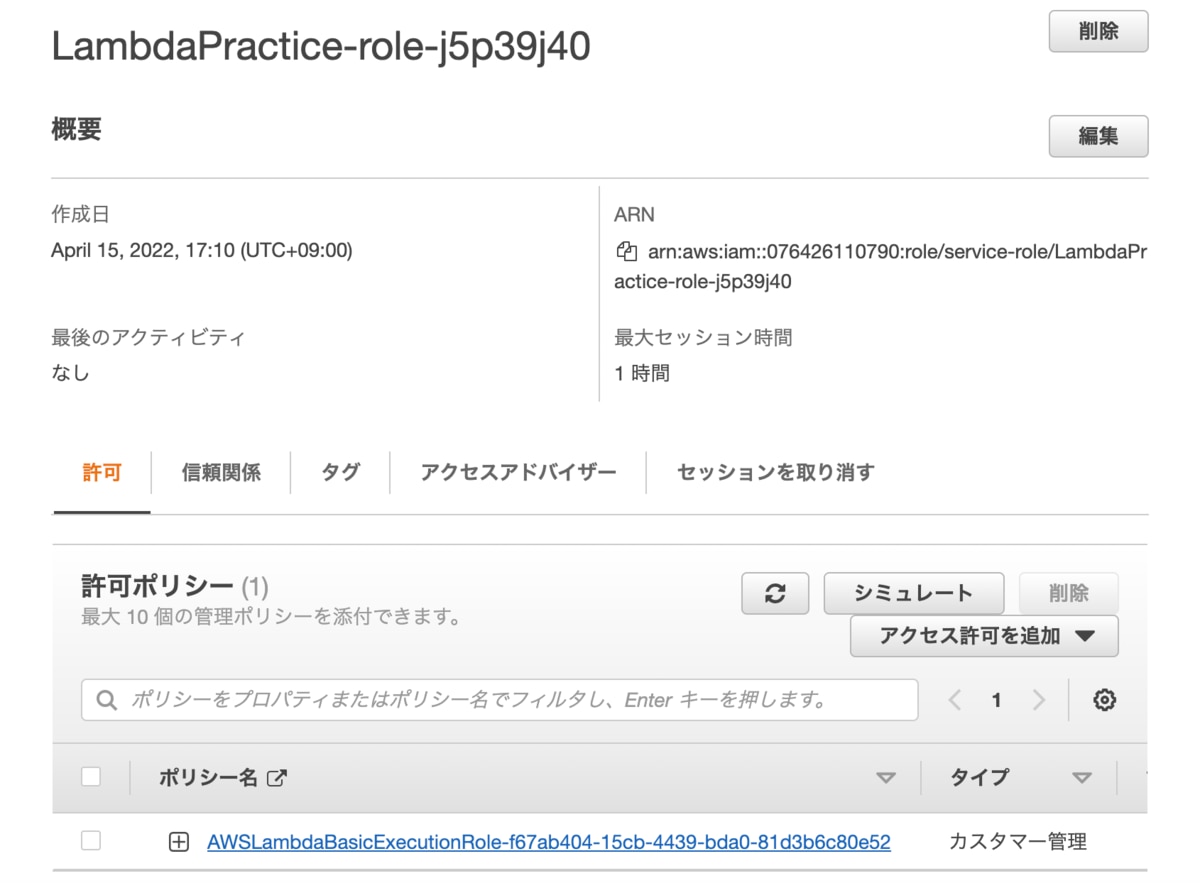
こんな感じで確かに「LambdaPractice」の名前でロールが作成されていました。
ポリシー名をクリックすると、詳細は以下の通り。
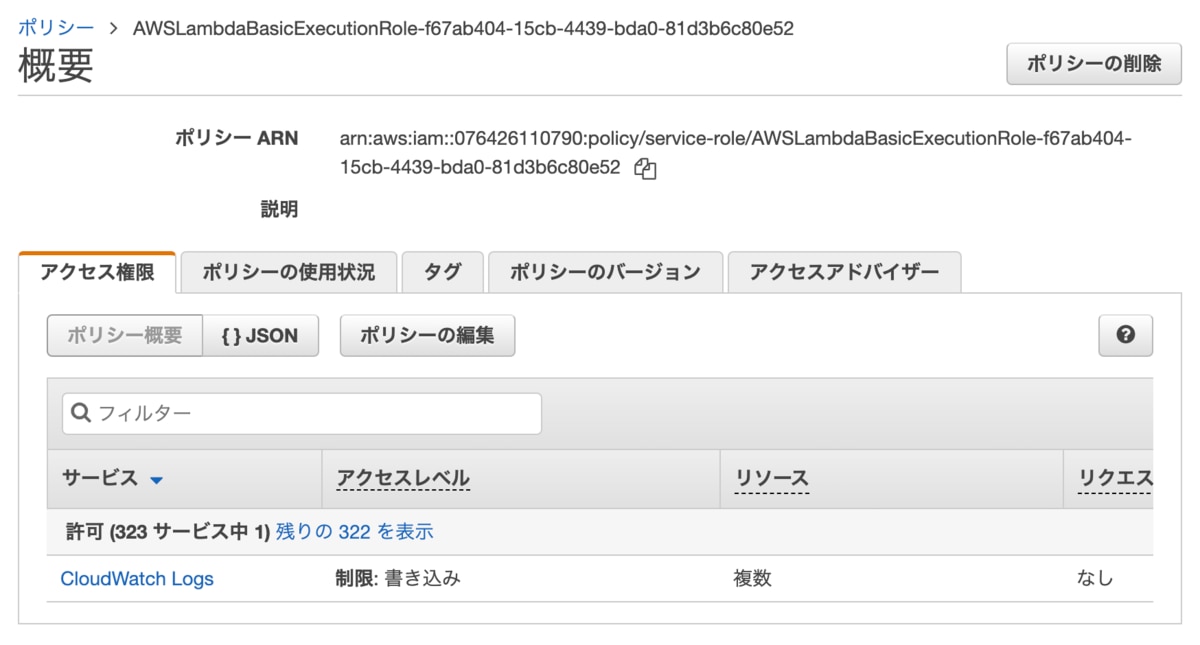
CloudWatch Logsに書き込み権限が与えられていることが確認できました。
ログを書き込む準備は整っていると言えます。
トリガーの追加
ここで再度作成の続きに戻りますね。
改めて先ほどの「LambdaPractice」の管理画面が以下です。
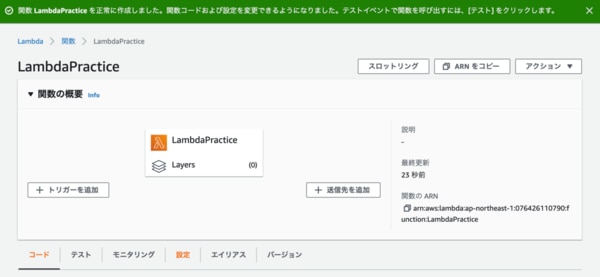
まずはトリガーを追加していきます。
トリガーというのは、Lambda関数を起動させる引き金のことでして、たとえば「S3にオブジェクトが保存されたらLambda関数起動!」みたいな感じでLambda関数を起動させる条件を指定することができます。
画面左側にある「トリガーを追加」をクリックすると以下の画面になります。
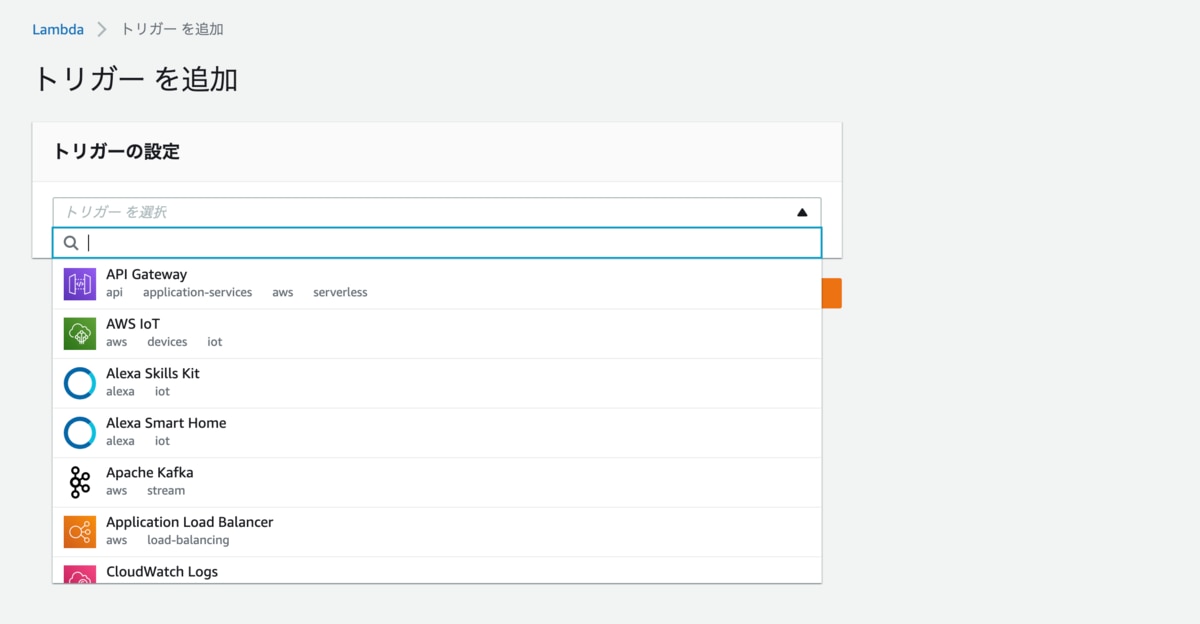
こんな感じでトリガーをプルダウンで選択できるようになっています。
今回はS3を選択してみます。
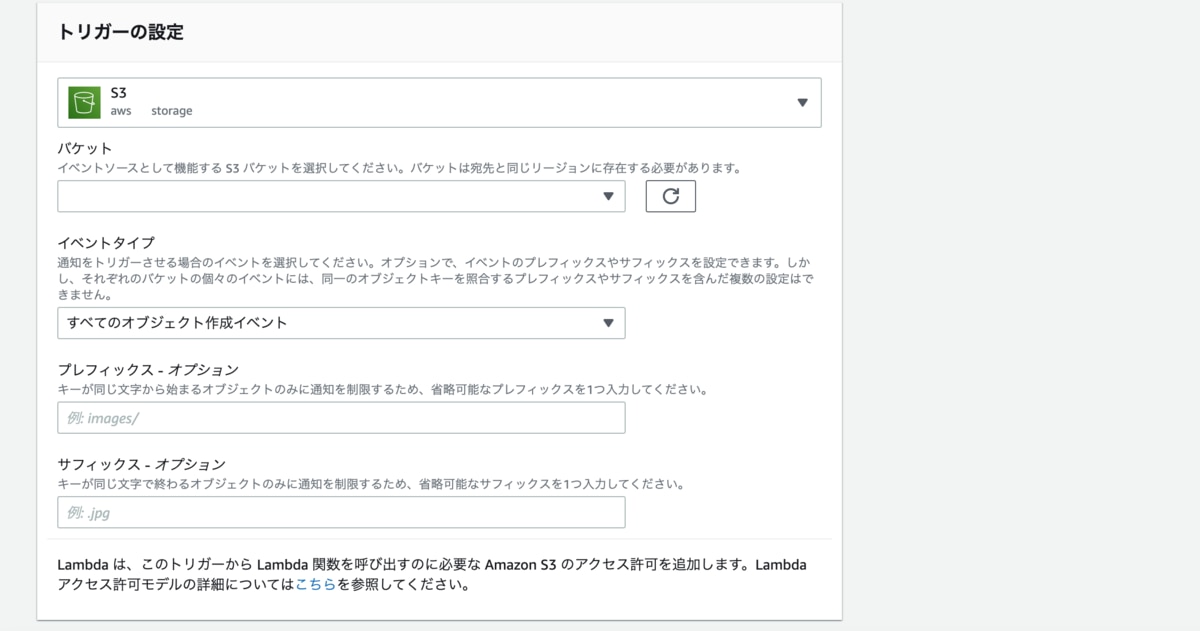
「バケット」や「イベントタイプ」が選択できるようになっていますね。
イベントタイプの選択はプルダウンになっていて、以下の感じ。
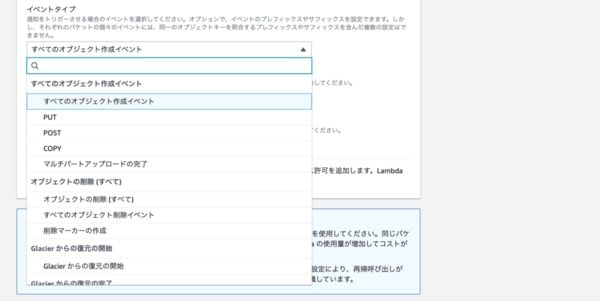
S3にオブジェクトが「作成された時」なのか、それとも「削除された時」なのか、Lambda関数を起動させるアクションを細かく選べるようになっています。
今回は「すべてのオブジェクト作成イベント」を選択して進めていきます。
送信先の追加
トリガーの設定が終わったら、今度は送信先の設定ですね。
Lambda関数を実行したら「その結果をどこに送信するのか」を指定していきます。
「送信先を追加」をクリックすると以下の画面になります。
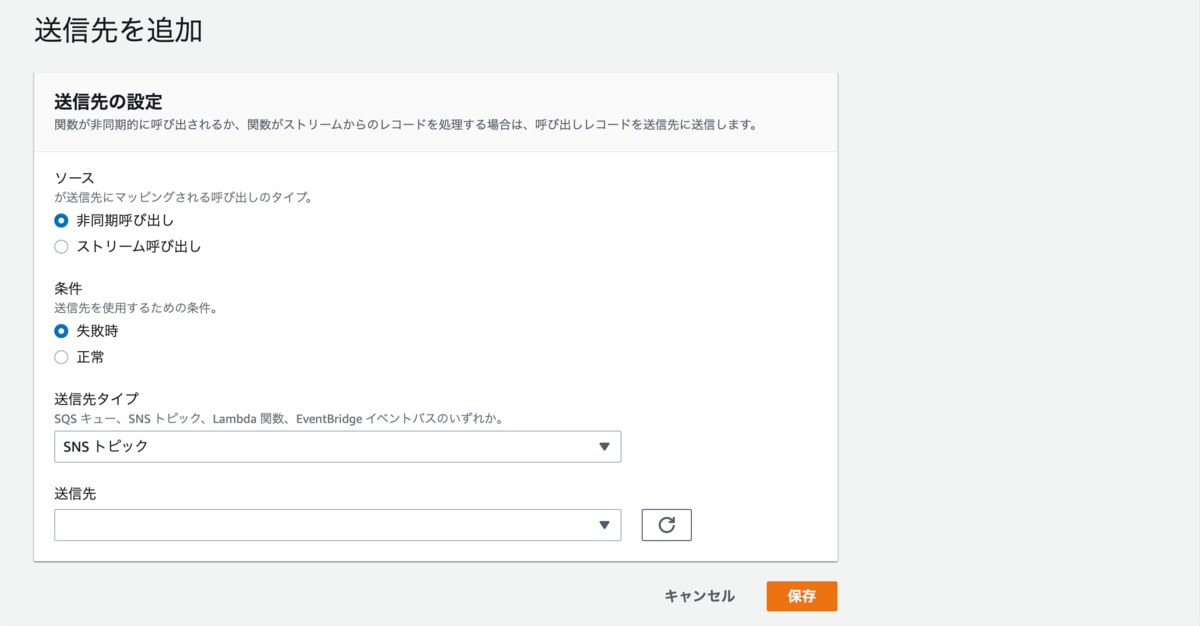
呼び出し方法は「非同期呼び出し」と「ストリーム呼び出し」から選択可能。
条件も「失敗時」と「正常時」が選択可能になっています。
こちらを選択し、保存ボタンを押したら作成完了ですね。
出来上がったLambda関数を実行してログを確認してみる。
というわけであっという間に作成が完了したので、早速出来上がったLambda関数を実行してみたいと思います。
その流れでCloudWatch Logsにログが書き込まれているかも確認していきます。
LambdaPracticeの管理画面を下にスクロールすると以下の画面があります。今回はここでテストを実行していきます。
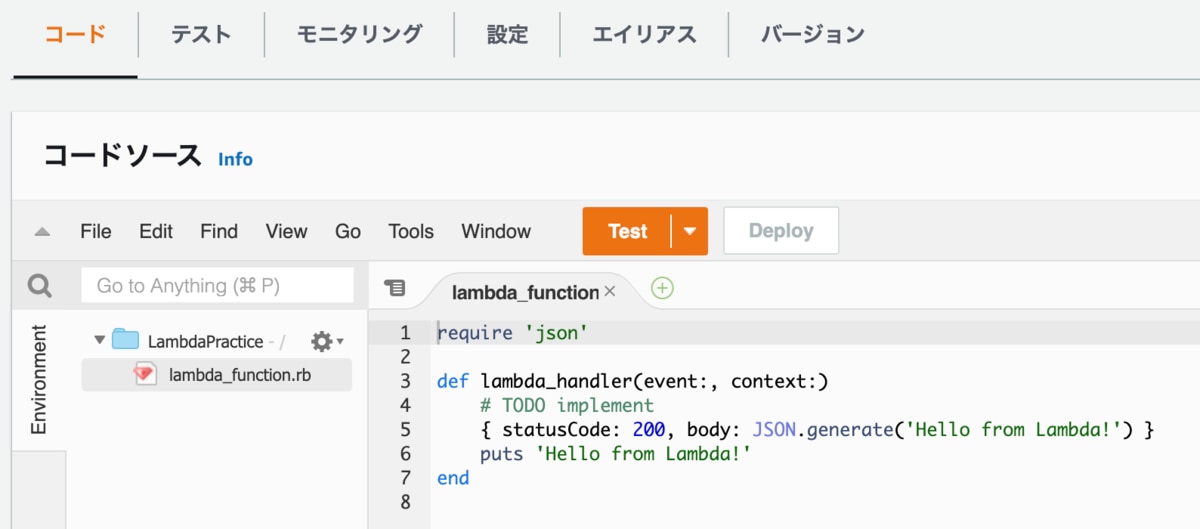
テストコードに「Hello from Lambda!」と出力するコードを記述しました。
これを実行してみます。

画像の通り実行に成功したとの表示が出たので、無事にテストが完了したようです。
早速CloudWatch Logsを確認しに行ってみます。
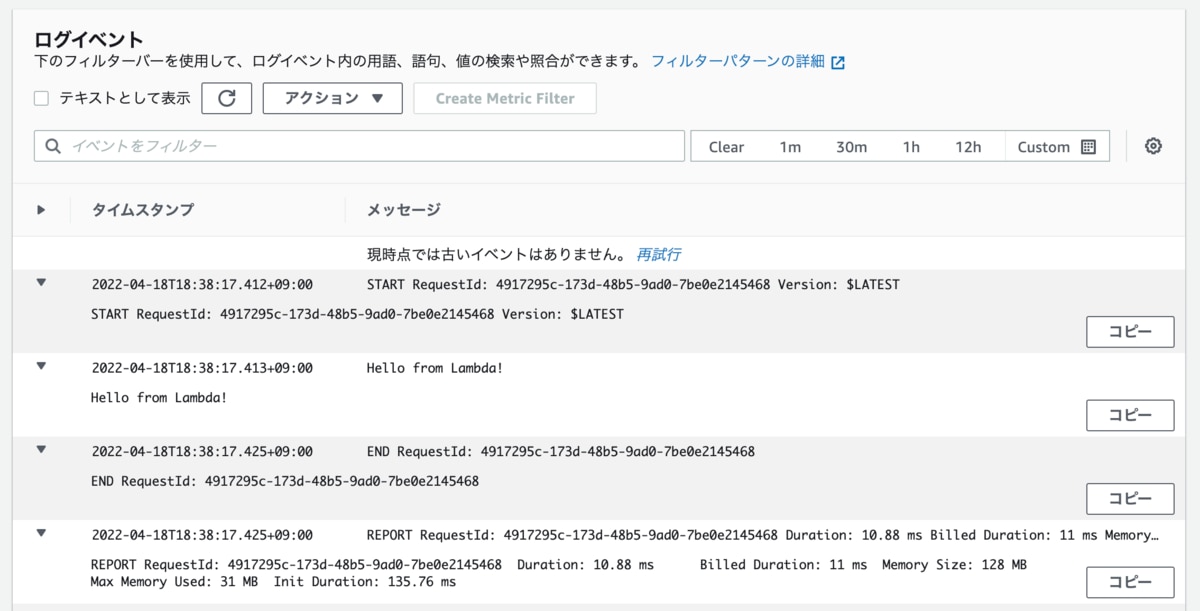
こちらがログのスクショでして、しっかり「Hello from Lambda!」と出力されていることが確認できますね。
ちゃんと保存されているようです。
今回つまずいたところ
というわけで今回の本題はここまでで終了です。
無事にLambda関数を作成して実行、ログを確認するところまでいきました。
せっかくなので今回の作成でつまずいたところをまとめておきます。
結論から言うと、「つまずいたところなどほとんどない。」という感じなのですが、強いて挙げるなら以下の2点ですね。
トリガーにS3を選択する際に以下の注意書きが出現。

トリガーにS3を選択したらこちらの注意書きが出てきます。
「入出力に同じバケットを指定すると、コスト増大の可能性がある。」という内容。
そりゃそうですね。
S3バケットに書き込み→Lambda呼び出し→結果を同じS3バケットに書き込み→Lambda呼び出し→以下略
永遠に実行されるのでコストが大変なことになるけどそれを認識してますよね?という確認ですね。
何度か作成を試していたら以下のエラーが出現。

今回の記事を書くため何度かLambda関数を作成したのですが、その途中でこちらのエラーに遭遇しました。
調べたらAWS公式にこのエラーについてのページがあったので以下に引用しますね。
参考
https://aws.amazon.com/jp/premiumsupport/knowledge-center/lambda-s3-event-configuration-error/
以下引用
このエラーは、次のいずれかの操作を行っているときに発生することがあります。 ・最近削除した S3 イベント通知を再作成している。 ・重複するプレフィックスまたはサフィックスを使用しながら、複数の重複するイベントに関する S3 イベント通知を作成している。
今回のケースだと1つ目で言われている「最近削除した S3 イベント通知を再作成している。」が該当しそう。
S3のオブジェクト作成イベントをトリガーにする関数を何度か作成したため、同じイベントでは作成できないというエラーだったということですね。
解決方法も掲載されていて以下の通り。
以下引用
以下のいずれかを実行します。 ・AWS CLI コマンド get-bucket-notification-configuration を実行して、S3 バケットの現在の通知設定を確認します。 ・Amazon S3 コンソールで既存の通知イベントを確認します。詳細については、イベント通知の有効化と設定を参照してください。
今回は2つ目の「Amazon S3 コンソールで既存の通知イベントを確認します。詳細については、イベント通知の有効化と設定を参照してください。」に心当たりあり。
S3コンソールの方に通知イベントが残っているとのことで確認。
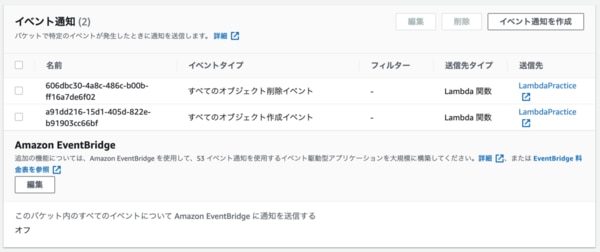
上の画像の通り、確かに残ってますね。
Lambda関数を削除しても、イベントを通知する側には通知イベント情報が残ってしまうので、削除するときはこっちも合わせて削除することを忘れずに。
まとめ
というわけで今回はAWSのサーバレスサービスの1つ「Lambda」について、実際にマネジメントコンソールを操作しつつ便利さを体験しました。
感想としては改めて書くまでもないですが、「めちゃ簡単」といったところですね。
ポチポチポチとクリックしていたらいつの間にか出来上がっていた感じ。確かにサーバーの存在を全く意識することなく関数作成することができました。素晴らしい。。。
これだけ簡単に作成できて、しかもコスパもいいときたら言うことないですね。
AWS側としても、使えるところはなるべくサーバレスサービスを利用することを推奨しているので、使えそうだと思ったらファーストチョイスで使っていくのが良さそうです。サーバレス最高!
今回は以上になります。
最後まで読んでいただきありがとうございました。
divxでは一緒に働ける仲間を募集しています。
興味があるかたはぜひ採用ページを御覧ください。
出典・参考資料
Lambda作成:
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/getting-started-create-function.html
トリガー:
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/lambda-edge-add-triggers-lam-console.html



