はじめに
こんにちは。株式会社divxのエンジニア谷口です。
最近開発でAWS SDK for Goを使ってS3からcsvファイルをダウンロードする機能を実装したのですが、数行のコードを書くだけで簡単に実装ができてしまい「こんなに簡単に実装できるの!?」と驚かされました。
しかしあまりの簡単さに「内部の仕組みもわからないまま実装できてしまったけどほんとにこれで大丈夫か?」という不安も同時に出てきてしまいました。
この記事をご覧になっている皆さんもAWS SDK for Goを使った実装はしたことあるけど、私のように実際のところ内部の仕組みまではわかっていないという方もいらっしゃるのではないでしょうか?
そこで今回はS3からのダウンロード実装例を元にソースコードリーディングを行い、SDK for Go内部でどのような処理が行われているのか深堀っていきたいと思います。
そして私と一緒に自信と安心感を手に入れていきましょう!
AWS SDK for Goとは?
SDKとは「Software Development kit」と呼ばれる開発キットの略称です。
そしてAWS SDK for Goという開発キットをAWSが提供しています。
AWS SDK for Goの公式サイトには以下のように書いています。
AWS SDK for Go を使用すると、AWS の使用を迅速に開始できます。この SDK を使用して、Amazon S3、Amazon DynamoDB、Amazon SQS などの AWS の各種サービスと Go アプリケーションを簡単に統合できます。
要するに、AWSの各種サービスとGoのアプリケーションを簡単に統合し、開発スピードや開発効率を上げてくれる便利なものというわけです。
またAWSのSDKではGo以外にもPython、PHP、Rubyなど様々な言語もサポートされています。
さっそく実装例を紹介します
※前提
AWS SDK for Goは現在v2が公開されていますが、基本的な書き方はv1と変わらないため今回はv1を使って説明させていただきます。
実際に手を動かして理解を進めたい方は公式のAWS SDK for Goの開始方法を参考に準備しましょう。
今回はS3にアップロードされているcsvファイルをダウンロードする機能について見ていきたいと思います。
準備しているS3の構成は以下のようになっています。
バケット名: sdk-for-go-test
フォルダ名: test-csv
ファイル名: sample.csv(この1ファイルのみアップロードされている)
sample.csvの中身はこのようになっています。
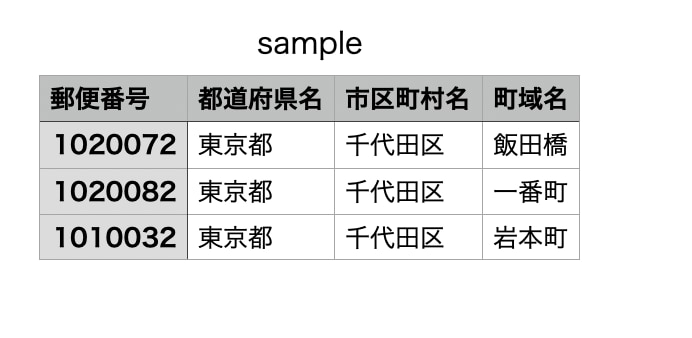
そしてダウンロード機能を実装したコードがこちらになります。
このサンプルコードはこちらのソースコードを参考に一部更したものとなっています。
package main
import (
"bytes"
"fmt"
"log"
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/s3"
"github.com/aws/aws-sdk-go/service/s3/s3manager"
)
func main() {
// セッションを作成
sess := session.Must(session.NewSessionWithOptions(session.Options{
SharedConfigState: session.SharedConfigEnable,
}))
bucket := "sdk-for-go-test"
key := "test-csv/sample.csv"
// downloaderを作成
downloader := s3manager.NewDownloader(sess)
// データの書き込み先を準備
buf := aws.NewWriteAtBuffer([]byte{})
// バケット名とキー名を指定してdownloadを行う
numBytes, err := downloader.Download(buf, &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
if err != nil {
log.Fatal(err)
}
fmt.Printf("Downloaded %v byte\n", numBytes)
// bytes.NewBuffer() でdownloadしたデータの中身を読み込むことができる
downloadData := bytes.NewBuffer(buf.Bytes()).String()
fmt.Printf("%#v", downloadData)
}
実行結果はこちらになります。

実行結果にはダウンロードしたファイルのサイズが206byteであること、そしてダウンロードしたcsvファイルの中身が出力されています。
コード上に補足でコメントは書いているのですが、ダウンロード機能のコードを読んでみると何を行っているのか直感的に分かりやすかったのではないでしょうか?
今回の機能をざっくりと分けると以下の4つで構成されています。
- セッションに必要な情報の設定
- downloaderを作成
- 書き込み先の準備
- S3からオブジェクトをダウンロード
この4つの流れでこれからソースコードリーディングを行い内部処理を理解していきましょう。
では1つずつ掘り下げていきます
1.セッション作成
ここでは以下の6つの関数が登場します。
|- session.Must()
|- session.NewSessionWithOptions()
|- session.loadSharedEnvConfig()
|- session.loaddEnvConfig()
|- session.envConfigLoad()
|- session.newSession()
※こちらのセッション作成に関しては深掘れる要素が複数あったためConfig設定に絞って掘り下げていきます。
// セッションを作成
sess := session.Must(session.NewSessionWithOptions(session.Options{
SharedConfigState: session.SharedConfigEnable,
}))
ここではクライアントとAWS間のセッションを確立させるために必要な情報を作成しています。
コードを見てみると「SharedConfigState」というオプションに「SharedConfigEnable」を設定しています。
この設定をすることにより、~/.aws/configや~/.aws/credentialsから設定やクレデンシャル情報を取得してくれるようになります。
ではその内部の仕組みを見るためにここに書かれた2つの関数を掘り下げていきましょう。
- session.Must()
- session.NewSessionWithOptions()
まずはsession.Must()のソースコードを見てみましょう。
aws/session/session.go
func Must(sess *Session, err error) *Session {
if err != nil {
panic(err)
}
return sess
}
Must()関数のコメントにはこのように書いています
// Must is a helper function to ensure the Session is valid and there was no
// error when calling a NewSession function.
訳)Must は、Session が有効であり、NewSession 関数を呼び出したときにエラーが発生しなかったことを確認するためのヘルパー関数です
つまり、Must内部ではセッションを作成する際に、「エラーがあったかどうか」というこの1点のみを確認するためだけの関数のようです。
そのため、エラーがあった場合はpanicを発生させ処理を強制終了し、エラーがなかった場合はそのままセッションを返しています。
次はsession.NewSessionWithOptions()のソースコードを見てみましょう。
名前から察するにセッションに対して何かオプションを追加していそうな関数に見えますね。
aws/session/session.go
func NewSessionWithOptions(opts Options) (*Session, error) {
var envCfg envConfig
var err error
if opts.SharedConfigState == SharedConfigEnable {
envCfg, err = loadSharedEnvConfig()
if err != nil {
return nil, fmt.Errorf("failed to load shared config, %v", err)
}
} else {
envCfg, err = loadEnvConfig()
if err != nil {
return nil, fmt.Errorf("failed to load environment config, %v", err)
}
}
if len(opts.Profile) != 0 {
envCfg.Profile = opts.Profile
}
switch opts.SharedConfigState {
case SharedConfigDisable:
envCfg.EnableSharedConfig = false
case SharedConfigEnable:
envCfg.EnableSharedConfig = true
}
return newSession(opts, envCfg, &opts.Config)
}
NewSessionWithOptions()関数のコメントを見てみましょう。
// NewSessionWithOptions returns a new Session created from SDK defaults,
// config files, environment, and user provided config files.
// This func uses the Options values to configure how the Session is created.
訳)NewSessionWithOptions は SDK のデフォルト、設定ファイル、環境、およびユーザー提供の設定ファイルから作成された新しいセッションを返します。この関数はOptions 値を使用して、Session の作成方法を設定します。
コメントを読んでみるとこの関数ではoptionsで渡した設定を反映させる処理を行っているようですね。
この関数の最後の返り値を見てみるとnewSession()関数の返り値を返しています。
そしてnewSession()へ渡している引数を見ると、envCfgなどの環境設定情報を新たに渡しているようです。
つまりoptionsで渡した設定をこのenvCfgに追加しているのではないか?と考えられますね。
そしてenvCfgは以下のような構造体となっています。
type envConfig struct {
// (〜中略〜)
Creds credentials.Value
Region string
Profile string
EnableSharedConfig bool
SharedCredentialsFile string
SharedConfigFile string
// (〜中略〜)
}
ここではRegionやProfileという設定に必要な情報などが定義されています。
このenvCfgのEnableSharedConfigというフィールドにoptionsで渡したSharedConfigState: session.SharedConfigEnableが関係していそうですね。
では続けて以下の条件分岐に注目してみます。
if opts.SharedConfigState == SharedConfigEnable {
envCfg, err = loadSharedEnvConfig()
if err != nil {
return nil, fmt.Errorf("failed to load shared config, %v", err)
}
} else {
envCfg, err = loadEnvConfig()
if err != nil {
return nil, fmt.Errorf("failed to load environment config, %v", err)
}
}
ここでoptionsで渡していた「SharedConfigState: session.SharedConfigEnable」に対して、「SharedConfigEnable」と一致したらloadSharedEnvConfig()を、そうでなければloadEnvConfig()を呼んでいます。
ここの処理でさっそくSharedConfigStateが使われましたね。
ではこの先にどういった処理の違いがあるのでしょうか。
続けてloadSharedEnvConfig()とloadEnvConfig()を見てみます。
aws/session/env_config.go
func loadEnvConfig() (envConfig, error) {
enableSharedConfig, _ := strconv.ParseBool(os.Getenv("AWS_SDK_LOAD_CONFIG"))
return envConfigLoad(enableSharedConfig)
}
func loadSharedEnvConfig() (envConfig, error) {
return envConfigLoad(true)
}
この2つの関数はどちらもenvConfigLoad()関数の返り値を返していることが確認できます。
そしてこの2つの関数では、NewSessionWithOptions()にSharedConfigEnableというオプションを渡していた場合はtrueを、そうでない場合は環境変数のAWS_SDK_LOAD_CONFIGを読み込みその結果のbool値をenvConfigLoad()の引数に渡しているようです。
次のenvConfigLoad()の関数名を見ると環境変数の設定を読み込んでいるんだろうなということがなんとなく想像できますね。
では続けてenvConfigLoad()のコードを見てみましょう。
aws/session/env_config.go
func envConfigLoad(enableSharedConfig bool) (envConfig, error) {
cfg := envConfig{}
cfg.EnableSharedConfig = enableSharedConfig
var creds credentials.Value
setFromEnvVal(&creds.AccessKeyID, credAccessEnvKey)
setFromEnvVal(&creds.SecretAccessKey, credSecretEnvKey)
setFromEnvVal(&creds.SessionToken, credSessionEnvKey)
if creds.HasKeys() {
creds.ProviderName = EnvProviderName
cfg.Creds = creds
}
// (~中略〜)
regionKeys := regionEnvKeys
profileKeys := profileEnvKeys
if !cfg.EnableSharedConfig {
regionKeys = regionKeys[:1]
profileKeys = profileKeys[:1]
}
// (中略)
return cfg, nil
}
この関数は最後にcfgという上記で説明したenvConfigという構造体の環境設定情報を返しています。
つまりこの関数のどこかで環境設定情報を追加する処理が行われていそうです。
続けて以下のコードを見てみます。
var creds credentials.Value
setFromEnvVal(&creds.AccessKeyID, credAccessEnvKey)
setFromEnvVal(&creds.SecretAccessKey, credSecretEnvKey)
ここで「AWS_ACESS_KEY」「AWS_SECRET_ACCESS_KEY」などの環境変数に設定した情報を読み込みcfgのフィールドの値に追加しているようです。
ここでさっそく環境変数の設定が反映されていましたね。
環境変数を追加しているcredsはenvConfigのフィールドに定義されています。
type envConfig struct {
// (〜中略〜)
Creds credentials.Value // ここに定義されています。
Region string
Profile string
EnableSharedConfig bool
SharedCredentialsFile string
SharedConfigFile string
// (〜中略〜)
}
このenvConfigLoad()関数では環境変数を読み込んでcfgに追加するという処理を行っていたようです。
次はこの関数で返されたcfg へ他の設定を追加しているnewSession()を見ていきましょう。
ここまで長くなってしまいましたが、次がセッションを作成するための最後の関数になります。
最後まで頑張って見ていきましょう!
ではnewSession()関数のソースコードを見てみます。
aws/session/session.go
func newSession(opts Options, envCfg envConfig, cfgs ...aws.Config) (Session, error) {
cfg := defaults.Config()
// (中略)
userCfg := &aws.Config{}
userCfg.MergeIn(cfgs...)
cfg.MergeIn(userCfg)
// (中略)
sharedCfg, err := loadSharedConfig(envCfg.Profile, cfgFiles, envCfg.EnableSharedConfig)
if err != nil {
if len(envCfg.Profile) == 0 && !envCfg.EnableSharedConfig && (envCfg.Creds.HasKeys() || userCfg.Credentials != nil) {
} else if _, ok := err.(SharedConfigProfileNotExistsError); !ok {
return nil, err
}
}
if err := mergeConfigSrcs(cfg, userCfg, envCfg, sharedCfg, handlers, opts); err != nil {
return nil, err
}
// (中略)
s := &Session{
Config: cfg,
Handlers: handlers,
options: opts,
}
// (中略)
return s, nil
}
ここでも色々と設定が追加されていそうですが、まずは最終的な返り値を見てみましょう。
この関数では最終的にs *Sessionを返しています。
Sessionという構造体は以下のように定義されています。
type Session struct {
Config *aws.Config
Handlers request.Handlers
options Options
}
Session構造体のコメントにはこのように書かれています。
// A Session provides a central location to create service clients from and
// store configurations and request handlers for those services.
訳)セッションはサービスクライアントを作成し、それらのサービスの設定とリクエストハンドラを保存するための中心的な場所を提供します。
中心的な場所という翻訳だと意味は分かりづらいですが、要するにこのSessionを作ることが今回のセッション作成のゴールとなっているということです。
つまりこのSessionという構造体がセッション本体の中身と考えていいと思います。
セッションはConfig、Handlers、optionsの3つで構成されていたことが分かりましたね。
では今回はConfigという設定に絞って掘り下げていたため、こちらのConfig部分に着目してみましょう。
こちらのコードを見てみます。
if err := mergeConfigSrcs(cfg, userCfg, envCfg, sharedCfg, handlers, opts); err != nil {
return nil, err
}
ConfigについてはこちらのmergeConfigSrcsで引数として渡してきた4つのcfgを最終的にマージしています。
cfg, userCfg, envCfg, ShredCfgと4種類あるのですが違いは以下となっています。
cfg: この関数の始めのdafaults.Config()で読まれるデフォルトの設定
userCfg: NewSessionWithOptions()の中で設定を行ったOptions構造体内のConfigの設定
envCfg: envConfigLoad()で環境変数から読み込んだ設定
SharedCfg: ~/.aws/config や ~/.aws/credentials などの設定ファイルから読み込んだ設定
今回の機能ではenvCfgとShredCfgの設定が追加されているため、この2つの設定がmergeConfigSrcsによってまとまったことになります。
ここまで長かったですが、以上がセッションを作成しているConfig設定の内部処理の仕組みでした。
では続けてdownloader作成の内部の仕組みを見ていきましょう!
2. downloader作成
ここでは以下の4つの関数が登場します。
|- s3.manager.NewDownloader()
|- s3.New()
|-s3.newClient()
|- s3.manager.newDownloader()
ではさっそくコードを読んでいきましょう。
// downloaderを作成
downloader := s3manager.NewDownloader(sess)
S3からオブジェクトをダウンロードするには、s3managerというpkgを使います。
pkgのドキュメントにはこう書かれています。
Package s3manager provides utilities to upload and download objects from S3
concurrently. Helpful for when working with large objects.
訳)s3managerパッケージは、S3からオブジェクトをアップロードおよびダウンロードするためのユーティリティを提供します。大きなオブジェクトを扱うときに便利です。
ダウンロードだけでなく、アップロード時にも使えるpkgとなっているようですね。
ではさっそくs3manager.NewDownloader()を掘り下げていきましょう。
S3manager/download.go
func NewDownloader(c client.ConfigProvider, options ...func(*Downloader)) *Downloader {
return newDownloader(s3.New(c), options...)
}
この関数のコメントを見ていきます。
// NewDownloader creates a new Downloader instance to downloads objects from
// S3 in concurrent chunks. Pass in additional functional options to customize
// the downloader behavior. Requires a client.ConfigProvider in order to create
// a S3 service client. The session.Session satisfies the client.ConfigProvider
// interface.
一部訳)NewDownloaderは、S3からオブジェクトを並列チャンクでダウンロードするための新しいDownloaderインスタンスを作成します。 追加の機能オプションを渡すと、ダウンローダーの動作をカスタマイズできます。session.Sessionはclient.ConfigProviderインタフェースを満たします。
要するにS3からオブジェクトをチャンク化して並列にダウンロードできるDownloaderインスタンスを新たに作成する関数のようですね。
先ほど1で作ったセッションsessが、client.ConfigProviderのインターフェースを満たすためこちらのNewDownloader()の第一引数として渡せるようです。
ちなみにclient.ConfigProviderとは以下のように定義されています。
type ConfigProvider interface {
ClientConfig(serviceName string, cfgs ...*aws.Config) Config
}
引数を見るとserviceNameとcfgsとあり、cfgsにはsessで設定した情報が入ると考えられますね。
serviceNameにはAWSのサービス名が入るため続く処理でサービス名としてS3が渡されます。
ではNewDownloader()に戻り、関数の返り値を見てみましょう。
func NewDownloader(c client.ConfigProvider, options ...func(*Downloader)) *Downloader {
return newDownloader(s3.New(c), options...)
}
この関数はnewDownloader()関数の返り値を返しています。
そして以下の2つの関数が新たに登場しましたね。
s3.New()で初期化してインスタンスを作成し、それを元にnewDownloader()でダウンローダーを作っているのかな?という風に考えられそうですね。
ではさっそくS3.New()から見ていきましょう。
s3/service.go
func New(p client.ConfigProvider, cfgs ...*aws.Config) *S3 {
c := p.ClientConfig(EndpointsID, cfgs...)
if c.SigningNameDerived || len(c.SigningName) == 0 {
c.SigningName = "s3"
}
return newClient(*c.Config, c.Handlers, c.PartitionID, c.Endpoint, c.SigningRegion, c.SigningName, c.ResolvedRegion)
}
この関数のコメントにはこのようにあります。
// New creates a new instance of the S3 client with a session.
// If additional configuration is needed for the client instance use the optional
// aws.Config parameter to add your extra config.
訳)Newは、セッションを持つS3クライアントの新しいインスタンスを作成します。 クライアントインスタンスに追加の設定が必要な場合は、オプションの aws.Configパラメータを使用して、追加の設定を追加します。
ここで第2引数のcfgsを渡すと新たな設定の追加ができるようですね。
けれど今回はs3.New(c)というように、第1引数の(p client.ConfigProvider )のみ渡していたためこちらの情報をもとにS3クライアントを作っていきます。
そしてs3.New()関数では最終的にnewClient()の返り値を返しています。
そのためこの関数で行っている処理はClientConfig()関数で設定を追加しているだけのようです。
c := p.ClientConfig(EndpointsID, cfgs...)
追加している設定を見てみましょう。
このs3pkgの定数は以下のように宣言されています。
const (
ServiceName = "s3" // Name of service.
EndpointsID = ServiceName // ID to lookup a service endpoint with.
ServiceID = "S3" // ServiceID is a unique identifier of a specific service.
)
そのためs3.New()関数のこの処理でs3が追加されることが分かりました。
c := p.ClientConfig(EndpointsID, cfgs...)
ではs3.New()関数の返り値で呼びでしているnewClient()を見ていきましょう。
s3/service.go
func newClient(cfg aws.Config, handlers request.Handlers, partitionID, endpoint, signingRegion, signingName, resolvedRegion string) *S3 {
svc := &S3{
Client: client.New(
cfg,
metadata.ClientInfo{
ServiceName: ServiceName,
ServiceID: ServiceID,
SigningName: signingName,
SigningRegion: signingRegion,
PartitionID: partitionID,
Endpoint: endpoint,
APIVersion: "2006-03-01",
ResolvedRegion: resolvedRegion,
},
handlers,
),
}
// Handlers
svc.Handlers.Sign.PushBackNamed(v4.BuildNamedHandler(v4.SignRequestHandler.Name, func(s *v4.Signer) {
s.DisableURIPathEscaping = true
}))
svc.Handlers.Build.PushBackNamed(restxml.BuildHandler)
svc.Handlers.Unmarshal.PushBackNamed(restxml.UnmarshalHandler)
svc.Handlers.UnmarshalMeta.PushBackNamed(restxml.UnmarshalMetaHandler)
svc.Handlers.UnmarshalError.PushBackNamed(restxml.UnmarshalErrorHandler)
svc.Handlers.BuildStream.PushBackNamed(restxml.BuildHandler)
svc.Handlers.UnmarshalStream.PushBackNamed(restxml.UnmarshalHandler)
// Run custom client initialization if present
if initClient != nil {
initClient(svc.Client)
}
return svc
}
この関数では最終的にsvcというサービスクライアントを返しています。
newClient()関数のコメントにはこのように書いています。
// newClient creates, initializes and returns a new service client instance.
訳)newClient は、新しいサービスクライアントのインスタンスを作成、初期化し、返す。
コメントにもあるようにここで最終的にS3のサービスを利用するためのサービスクライアントを作成しています。
では最後にこのサービスクライアントを用いて作られるnewDownloader()を見ていきましょう。
s3manager/download.go
func newDownloader(client s3iface.S3API, options ...func(*Downloader)) *Downloader {
d := &Downloader{
S3: client,
PartSize: DefaultDownloadPartSize,
Concurrency: DefaultDownloadConcurrency,
BufferProvider: defaultDownloadBufferProvider(),
}
for _, option := range options {
option(d)
}
return d
}
第1引数のclient s3icace.S3APIに先程作成したサービスクライアントが渡されます。
そしてこの関数ではDownloaderの動作のカスタマイズを以下の宣言箇所で行っているようです。
d := &Downloader{
S3: client,
// S3に要求する最小のバイト数を設定(デフォルトでは5MB)
PartSize: DefaultDownloadPartSize,
// ゴルーチンで並行処理する数の設定(デフォルトでは5)
Concurrency: DefaultDownloadConcurrency,
// ダウンロードする際の使用されるバッファを指定
BufferProvider: defaultDownloadBufferProvider(),
}
コメントにて書いていたような設定の追加がこの宣言で可能となっています。
そしてこの設定を追加したダウンローダーをdとして返しているようです。
ここまでがダウンローダー作成の内部処理となります。
1~2の流れを見てみましたが、1ではセッションを作り、2ではダウンローダーを作るという役割が明確に分けられているんだなということを、内部処理を見てみると改めて感じました。
ただ単に表面上のコードだけ追っているとわからないことも、内部処理を見てみるといろいろな発見があって楽しいですね!
では続けてダウンロードしたデータを書き込む書き込み先の処理について見ていきましょう!
3. 書き込み先の準備
// 書き込み先を準備
buf := aws.NewWriteAtBuffer([]byte{})
こちらはダウンロードしたデータをメモリに書き込むための内部バッファを作成しています。
ではNewWriteAtBuffer()の中身を見てみましょう。
func NewWriteAtBuffer(buf []byte) *WriteAtBuffer {
return &WriteAtBuffer{buf: buf}
}
この関数はWriteAtBufferという構造体を返しているだけのようですね。
そしてWriteAtBufferは以下のような構造体となっています。
type WriteAtBuffer struct {
buf []byte
m sync.Mutex
GrowthCoeff float64
}
こちらのbufというフィールドに対して引数で渡した[]byte{}を設定しています。
こうすることでS3のコンテンツをメモリの内部バッファにダウンロードできるようにしています。
短かったですが、以上が書き込み先の準備の内部処理となっていました。
ちなみにこの書き込み先を以下のようにするとS3上のcsvファイルをローカルにダウンロード(ローカル上にexample.csvという名前でダウンロードしたファイルを作成)してくれるようになります。
// buf := aws.NewWriteAtBuffer([]byte{})
buf, err := os.Create("example.csv")
if err != nil {
panic(err)
}
defer buf.Close()
ではようやく最後の処理となるダウンロードを次から見ていきましょう!
4. S3からオブジェクトをダウンロード
ここでは以下の6つの関数が登場します。
|- Downloader.Download()
|- Downloader.DownloadWithContext()
|- downloader.download()
|- downloader.getChunk()
|- downloader.downloadChunk()
|- downloader.tryDownloadChunk()
そしてダウンロードのコードがこちらになります。
// バケット名とキー名を指定してdownloadを行う
numBytes, err := downloader.Download(buf, &s3.GetObjectInput{
Bucket: aws.String(bucket),
Key: aws.String(key),
})
if err != nil {
log.Fatal(err)
}
ここでは今まで準備してきたセッション、downloader、書き込み先のbufを使って実際にダウンロード処理を行う箇所となっています。
この処理は見たところbuf、s3.GetObjectInputやBucket,Keyとあるのでこの4つを使ってS3から指定したオブジェクトを取ってきているんだろうなと想像できますね。
ではさっそく内部処理を見ていきましょう。
s3manager/download.go
func (d Downloader) Download(w io.WriterAt, input s3.GetObjectInput, options ...func(Downloader)) (n int64, err error) {
return d.DownloadWithContext(aws.BackgroundContext(), w, input, options...)
}
ここではすぐにDownloadWithContext()の返り値を返しているようです。
Download()という関数を呼んでいるようで中では別のDownloadWithContext()を呼んでいたんですね。
ここでの違いはDownloadWithContext()の第一引数としてContextを渡しています。
Contextがnilの状態でDownloadWithContextに渡されるとパニックを起こしてしまうため、aws.BackgroundContext()で空のContextを作成しています。
Contextを初めから渡す場合は、Download()ではなく、DownloadWithContext()を呼んで実装することも可能です。
では続けてDownloadWithContext()の中身を見てみましょう。
s3manager/download.go
func (d Downloader) DownloadWithContext(ctx aws.Context, w io.WriterAt, input s3.GetObjectInput, options ...func(Downloader)) (n int64, err error) {
if err := validateSupportedARNType(aws.StringValue(input.Bucket)); err != nil {
return 0, err
}
impl := downloader{w: w, in: input, cfg: d, ctx: ctx}
for _, option := range options {
option(&impl.cfg)
}
impl.cfg.RequestOptions = append(impl.cfg.RequestOptions, request.WithAppendUserAgent("S3Manager"))
if s, ok := d.S3.(maxRetrier); ok {
impl.partBodyMaxRetries = s.MaxRetries()
}
impl.totalBytes = -1
if impl.cfg.Concurrency == 0 {
impl.cfg.Concurrency = DefaultDownloadConcurrency
}
if impl.cfg.PartSize == 0 {
impl.cfg.PartSize = DefaultDownloadPartSize
}
return impl.download()
}
この関数のコメントにはこのように書いてあります。
// DownloadWithContext downloads an object in S3 and writes the payload into w
// using concurrent GET requests. The n int64 returned is the size of the object downloaded
// in bytes.
訳)DownloadWithContextは、S3のオブジェクトをダウンロードし、同時GETリクエストを使ってwにペイロードを書き込む。 返されるn個のint64は、ダウンロードされたオブジェクトのサイズでバイトで返される。
要するに、第2引数としている w io.WriteAtにダウンロードしたデータを書き込み、この関数の返り値としてダウンロードしたオブジェクトのサイズをbyte単位で返す関数ということです。
この関数の最後ではimpl.download()の結果が返されています。
つまりimple.download()の結果は、ダウンロードしたオブジェクトサイズ(byte)が入ってくることは想像ができますね。
まずはDownloadeWithContext()関数のこちらの記述に注目してみましょう。
impl := downloader{w: w, in: input, cfg: d, ctx: ctx}
ここではimplという変数に対し、downloader{}の構造体を使って宣言されていますね。
downloaderの構造体はこのようになっています。
type downloader struct {
ctx aws.Context
cfg Downloader
in *s3.GetObjectInput
w io.WriterAt
wg sync.WaitGroup
m sync.Mutex
pos int64
totalBytes int64
written int64
err error
partBodyMaxRetries int
}
cfgやGetObjectInputで渡された値、データをダウンロードして書き込むw などダウンロードに必要なフィールドが集約されています。
つまりこの関数ではダウンロードの実施を行う前に必要な追加情報の設定を行っているようです。
では実際にdownloadを行っていそうなimple.download()関数の内部処理を見てみましょう。
s3manager/download.go
func (d *downloader) download() (n int64, err error) {
if rng := aws.StringValue(d.in.Range); len(rng) > 0 {
d.downloadRange(rng)
return d.written, d.err
}
d.getChunk()
if total := d.getTotalBytes(); total >= 0 {
ch := make(chan dlchunk, d.cfg.Concurrency)
for i := 0; i < d.cfg.Concurrency; i++ {
d.wg.Add(1)
go d.downloadPart(ch)
}
for d.getErr() == nil {
if d.pos >= total {
break
}
ch <- dlchunk{w: d.w, start: d.pos, size: d.cfg.PartSize}
d.pos += d.cfg.PartSize
}
close(ch)
d.wg.Wait()
} else {
for d.err == nil {
d.getChunk()
}
e, ok := d.err.(awserr.RequestFailure)
if ok && e.StatusCode() == http.StatusRequestedRangeNotSatisfiable {
d.err = nil
}
}
return d.written, d.err
}
この関数の最後の返り値では、先ほどのコメントに書いてあったとおりd.writtenとしてn int64が返されていますね。
この中身はダウンロードされたデータのサイズ(byte)となります。
ではこのdownload()関数の中でダウンロードを行っている箇所を見てみましょう。
ダウンロードはこのgetChunk()関数で行っています。
ダウンロードという言葉から連想するとdownload()のような関数があると考えていたのですが違いました。
ではgetChunk()の内部処理を見てみましょう。
s3manager/download.go
func (d *downloader) getChunk() {
if d.getErr() != nil {
return
}
chunk := dlchunk{w: d.w, start: d.pos, size: d.cfg.PartSize}
d.pos += d.cfg.PartSize
if err := d.downloadChunk(chunk); err != nil {
d.setErr(err)
}
}
ここではchunkという名前でdlchunk{}という以下の構造体が宣言されています。
type dlchunk struct {
w io.WriterAt
start int64
size int64
cur int64
// specifies the byte range the chunk should be downloaded with.
withRange string
}
この構造体のフィールドには書き込み先や開始位置、そしてサイズなどの情報が定義されています。
そしてこの構造体を元にd.downloadChunk(chunk)を行っています。
s3manager/download.go
func (d *downloader) downloadChunk(chunk dlchunk) error {
in := &s3.GetObjectInput{}
awsutil.Copy(in, d.in)
in.Range = aws.String(chunk.ByteRange())
var n int64
var err error
for retry := 0; retry <= d.partBodyMaxRetries; retry++ {
n, err = d.tryDownloadChunk(in, &chunk)
if err == nil {
break
}
if bodyErr, ok := err.(*errReadingBody); ok {
err = bodyErr.Unwrap()
} else {
return err
}
chunk.cur = 0
logMessage(d.cfg.S3, aws.LogDebugWithRequestRetries,
fmt.Sprintf("DEBUG: object part body download interrupted %s, err, %v, retrying attempt %d",
aws.StringValue(in.Key), err, retry))
}
d.incrWritten(n)
return err
}
この関数のコメントにはこう書いてあります。
// downloadChunk downloads the chunk from s3
訳) downloadChunk は S3 からチャンクをダウンロードします。
ここでは最終的にerrを返しているため、ダウンロードが成功した場合はd.incrWritten(n)でデータの書き込み処理を行っています。
そして実際のダウンロード処理はこの関数の中の以下の関数で行われています。
n, err = d.tryDownloadChunk(in, &chunk)
では最後にtryDownloadChunk()の内部処理を見てみましょう。
s3manager/download.go
func (d *downloader) tryDownloadChunk(in *s3.GetObjectInput, w io.Writer) (int64, error) {
cleanup := func() {}
if d.cfg.BufferProvider != nil {
w, cleanup = d.cfg.BufferProvider.GetReadFrom(w)
}
defer cleanup()
resp, err := d.cfg.S3.GetObjectWithContext(d.ctx, in, d.cfg.RequestOptions...)
if err != nil {
return 0, err
}
d.setTotalBytes(resp) // Set total if not yet set.
var src io.Reader = resp.Body
if d.cfg.BufferProvider != nil {
src = &suppressWriterAt{suppressed: src}
}
n, err := io.Copy(w, src)
resp.Body.Close()
if err != nil {
return n, &errReadingBody{err: err}
}
return n, nil
}
このtryDownloadChunk()関数にダウンロードを実行している処理の本体がありました。
それはこちらです。
resp, err := d.cfg.S3.GetObjectWithContext(d.ctx, in, d.cfg.RequestOptions...)
if err != nil {
return 0, err
}
d.setTotalBytes(resp) // Set total if not yet set.
ダウンロード処理の内部ではGetObjectWithContext()でS3からデータを取得しているのですね。
そしてその結果をsetTotalBytes()関数がデータの合計値である総byte数を返していました。
以上、ここまでがS3からオブジェクトをダウンロードする処理の流れとなっています。
download()という関数からこの関数が呼び出されるまで多くの処理がありましたね。
ここまで読んでいただき本当にありがとうございました!
※補足
ダウンロード実装例のコードには以下のようにダウンロードしたデータを表示するコードがありますが、ここはダウンロード機能処理の本質とは外れるため説明は割愛します。
fmt.Printf("Downloaded %v byte\n", numBytes)
// bytes.NewBuffer() でdownloadしたデータの中身を読み込むことができる
downloadData := bytes.NewBuffer(buf.Bytes()).String()
fmt.Printf("%#v", downloadData)
ここの処理はダウンロードしたデータサイズの表示と、byteのデータをStringに変換する処理を挟みデータの中身を文字列として表示しているシンプルなものとなっています。
おわりに
これでAWS SDK for Goのダウンロード内部処理のソースコードリーディングは終わりとなります。
みなさん読んでみていかがだったでしょうか?
「なるほど、そうだったのか!」「へぇ〜」「ここもうちょっと詳しく知りたいな」など色々な感想があるかと思いますが、この記事を通して少しでも発見や気付きがあったのなら嬉しいです。
そして読む前に比べて少しでも興味が湧いた場合は是非ご自身でソースコードを読んでみてください!
ソースコードリーディングが苦手な私でも読んでいくうちに楽しさに気づくことができました。
最初は苦しく感じることもありますが、読んでみて理解が進むと「内部ではこんなに細かく役割が分けられて実装されているんだ」や「こうすることで変更に柔軟に対応できるんだ」など発見が多く楽しかったです。
ここまで長かったですが最後までお付き合いいただき、ありがとうございました。
divxでは一緒に働ける仲間を募集しています。
興味があるかたはぜひ採用ページを御覧ください。
参考文献





