

無料、初心者向け、所要時間30分。Google ColaboratoryとHugging Face、最初の一歩
はじめに
こんにちは。株式会社divx エンジニアの安部です。
ChatGPT等のAIチャットツール、Cursor等のAIを組み込んだ開発ツール、OpenAIのAPIを使ったサービス等、いよいよAIが開発現場や日常に深く潜り込んできましたね。
LLM(Large Language Model:大規模言語モデル)も一般教養として知っておきたい単語になってきています。多くの企業がLLMを公開しており、様々な学習データを簡単に試せるようになっています。
この記事は、これからAIシフトをする際に利用するかもしれない以下の2つのサービスに触れてもらうことを目的に書きました。
- Google Colaboratory
- Hugging Face
「LLM 使い方」などのワードで検索してみると、はっきりと「無料でできる範囲でLLMを使ってみよう」という記事が少ないです。
というのも、後述の通りLLMは「さらなる学習」を目的に利用されることが多いので、制約の多いGoogle Colaboratoryの無料版はあまり利用されません。
本記事は実務であまりプログラミングをしない方や駆け出しエンジニアの方でも触れるところまでを想定しています。お金も時間もかかりません。
この記事を「LLM入門編」として、興味が湧いた方は課金してファインチューニングを試してみてください。
大規模言語モデル(LLM)とは?
LLMの概要
LLM(Large Language Model:大規模言語モデル)とは、多くのデータをもとに訓練された人工知能(AI)の一種です。
AIを「プレーンな状態」→「訓練した状態」→「さらに訓練した状態」に分けるとわかりやすいです。
「プレーンな状態」では、特定のタスクを行う能力が高くなく、あまり役に立ちません。
「訓練した状態」では、大量のデータをもとに言語処理や画像生成を学ばせた状態になります。このとき、損失関数(予測値と実際の正解値のズレを計算する関数)の結果が最小になることを目指します。つまり、想定する正解に近づけていく作業です。LLMは、一般にこの状態で公開されています。
ファインチューニング
「さらに訓練した状態」はファインチューニングとも言われます。訓練した状態で公開されたLLMに対して、更に特定の領域の能力を伸ばすために独自に訓練する作業です。
たとえば、一般的な画像生成ができるモデルに対して、特定の作家の絵を大量に読み込ませることで「その作家っぽい絵柄に特化したAIモデル」を作ることができます。このようなファインチューニングは、公開済みのモデルを利用して個人が行うことが多いです。
今回は「訓練した状態」のAIモデルを無料で利用する方法を書きます。応用すればファインチューニングも行えますが、課金が必要になります。
事前知識
Google Colaboratoryとは?
Googleが提供する、ブラウザから直接Pythonを記述・実行できるサービスです。主な特徴は以下のとおりです。
- 環境構築が不要
- GPU に無料でアクセスできる
- 簡単に共有できる
特に「GPU」についてはGPU RAM10-15GBのスペックのものを無料で利用できます。
無料で使う場合の注意点は以下の通りです。 - 無料版ではGPU使用量の上限等でしばしば使えなくなる。(平均24時間程度で復帰します。)
- 操作しないまま90分放置すると環境がリセット。
- インスタンス起動後12時間経つとリセット。
本格的に使いたい方は「Google Colab Pro」に月額1200円程度を課金すると、更にスペックが高く、永続的な利用が可能になります。
参考:Google Colaboratory
Hugging Faceとは?
機械学習、自然言語処理のモデルを共有するためのプラットフォームです。
AI版Githubみたいなものです。
今回使うモデルの使い方はいずれもHugging Faceのページを参照しています。
参考:Hugging Face – The AI community building the future.
Google Colaboratoryにノートブック追加
Google Colaboratoryのプロジェクト単位を「ノートブック」と呼びます。
まずはGoogle Driveに接続します。右上の「新規作成」→「その他」→「Google Colaboratory」を選択します。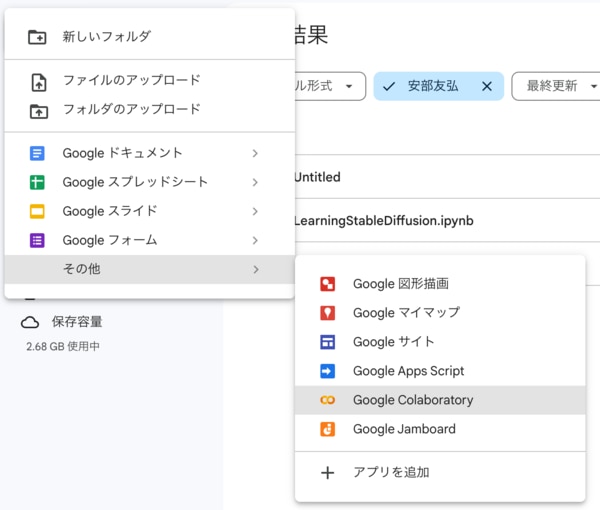
Noteの名前はDriveアイコンの横の「Untitled」をクリックして変更します。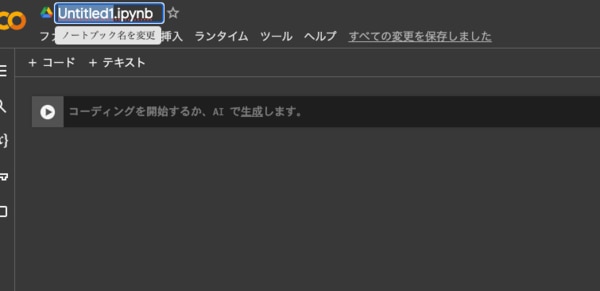
続いて、ランタイムタイプを変更します。今回はPythonを使い、画像生成のモデルも使いたいのでGPUを使います。設定は以下の通り。
- ランタイムのタイプ:Python 3
- ハードウェア アクセラレータ:T4 GPU
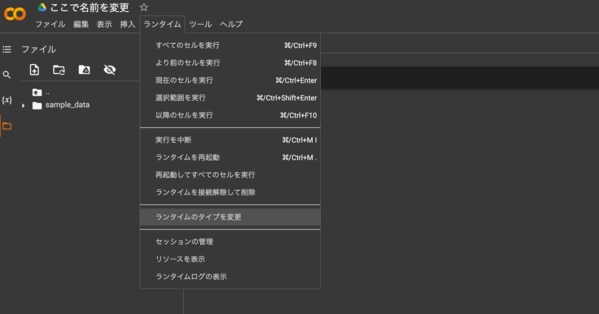
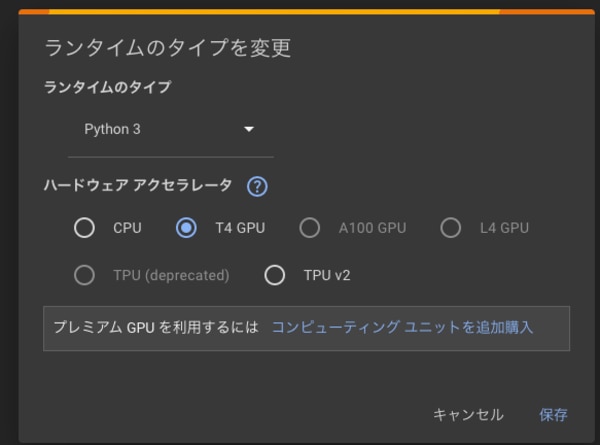
これで、Pythonコードを入力するだけで実行できます。
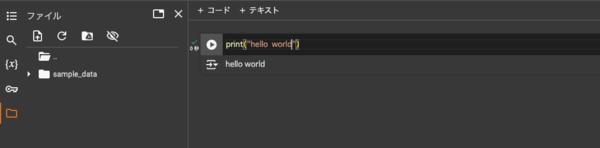
以上でノートブックの準備は完了です。
今回使用するAIモデル
Google Colaboratoryの無料版で利用できるマシンスペックだと、高性能なLLMは満足に動作しません。「LLM 軽量」などのワードで検索して出てくるモデルを試行錯誤で動かしていく必要があります。
以下は、私が試した範囲で動作したモデルです。
Stable Diffusion
画像生成系のメジャーなAIモデルです。
無料で簡単に画像生成ができます。
CompVis/stable-diffusion-v1-4 · Hugging Face
LINE DistilBERT Japanese
LINEが公開している自然言語処理のモデルです。今回は、マスクされた文章を予測するという使い方をしてみようと思います。
https://huggingface.co/line-corporation/line-distilbert-base-japanese
各モデルの使い方
おそらく、Python未経験の方やHugging Faceの説明の読み方がわからない方もいるかと思います。
ここも簡単で、Hugging Faceにアクセスして最初に出てくる"Model Card”の情報をChatGPTにコピペすると大まかな使い方を教えてくれます。
質問フォーマット
ChatGPTの回答(要約)
このREADMEは、Stable Diffusion v1-4モデルに関する詳細な情報と、Pythonを使用してこのモデルを利用するための手順を提供しています。
(中略)
必要なライブラリのインストール
まず、必要なパッケージをインストールします。これには、diffusers、transformers、scipyが含まれます。
PyTorchを使用してStable Diffusionを実行
以下のコードスニペットは、PyTorchを使用してStable Diffusionモデルを実行する方法を示しています。
利用用途と注意点
モデルの利用は研究目的に限られ、以下のような用途が含まれます。
(中略)
これらのコードスニペットと説明を使用して、Stable DiffusionモデルをPythonで実行し、様々なテキスト入力から画像を生成することができます。
各ファイルを記述、格納
ファイルを新規作成
ファイルアイコンをクリックして新しいファイルを選択し、ファイル名を入力します。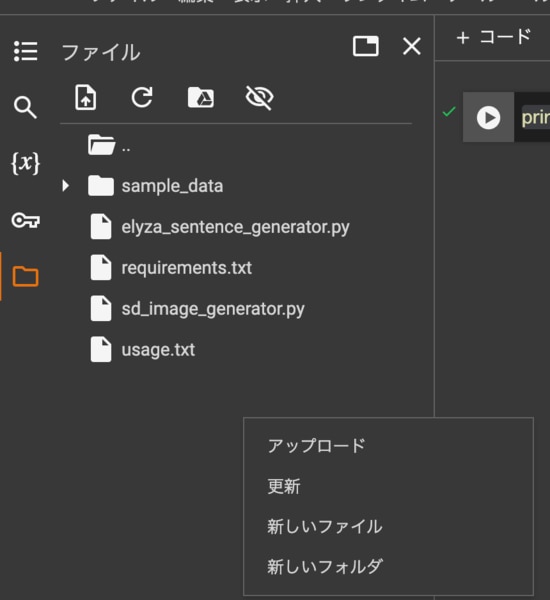
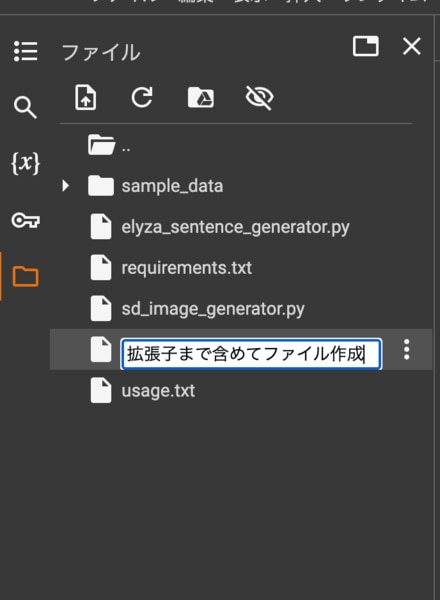
作成するファイル名は以下のとおりです。
- line_distilbert_sentence_generator.py
LINE DistilBERT Japaneseで日本語文章の穴埋め予測をするコードです。 - requirements.txt
必要なパッケージを記述、一括でインストールできるようにするファイルです。 - sd_image_generator.py
Stable Diffusionで画像生成するためのコードです。 - usage.txt
コマンドの使い方、インポート方法等を記載したファイルです。
下記のフォルダ構成になっていればOKです。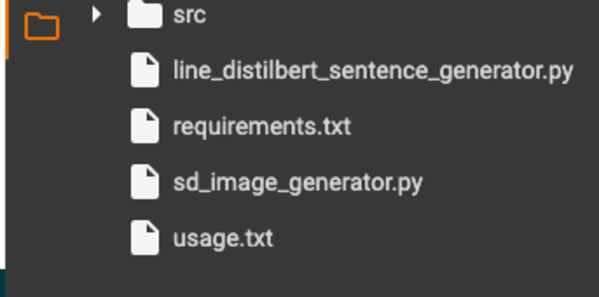
各ファイルの記述
今回は繰り返し処理を想定して記述しています。各コードを読んで、必要に応じて書き換えてください。
コードの内容が分からない場合は、Hugging Faceの該当ページを参照して、ChatGPTも併用して読み解いていきましょう。
想定した動きになるよう、ChatGPTを用いてコードを加筆しています。
また、一定時間が経過するとすべてのファイルが消えますので、PCのローカルに用意して、バックアップしておくことをおすすめします。
sd_image_generator.py
line_distilbert_sentence_generator.py
requirements.txt
usage.txt
実行
GUIの説明と実行時に便利なショートカットキー
「+コード」ボタンで次の行を追加してPythonコードを打ち込み、再生ボタンで実行します。
実行したコードを再度実行したい場合はGUI上の再生ボタンで実行できます。
また、ファイル名をクリックすると右側にファイルの内容が表示され、編集できます。エラー時にお試しください。
また、以下のコマンドを入力することでショートカットも可能です。
-
cmd + Enter
コードを実行 -
Shift + Enter
コードを実行し、次のコード入力行を追加。
必要なパッケージをインストール
最初に、必要なパッケージを以下のコマンドでインストールします。
下記のようにログが出てきて、結構時間がかかります。
インストールが終わると「RESTART RUNTIME」のアラートが出てきます。パッケージをインストールした後にはランタイムの再起動が必要です。
また、インストールするパッケージが多いので、中断する場合もあります。複数回実行しましょう。
Stable Diffusionで画像生成
パッケージがインストールできたら、Stable Diffusionに接続して画像を生成してみます。
以下のコマンドを打ちます。
打ち込むと「1を入力してください」という指示が出てくるのでキーボードの半角1を打ち込みます。
続いて英語で、生成したい画像のテーマを打ち込みます。初回は必要なパッケージを諸々インストールするので、画像生成も含めて3分程度かかります。
生成された画像は「sd_images」に保存されます。
下図のようにフォルダとファイルが確認できれば成功です。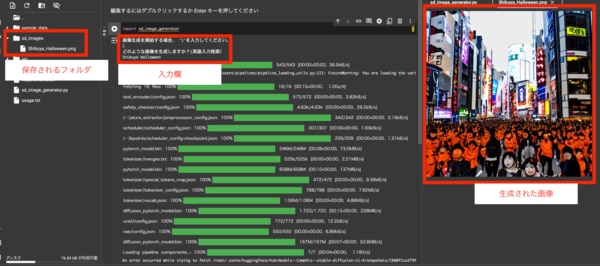
上記スクリーンショットに写った画像は「Shibuya Halloween」と打ち込んで生成された画像です。
渋谷の町並みの中に、ハロウィンのかぼちゃ、ジャック・オー・ランタンのような人々が並んでいます。(ちょっと怖いので、スクリーンショット内でお楽しみください。)
Stable Diffusionの今回使ったモデルは、やや油絵的なタッチの画像が生成されることが多いようです。
LINE DistilBERT Japanese で日本語の穴埋め予測
これも上記と同様、以下のコマンドを実行して指示通りに進めていくと日本語の文章が生成されます。
下記のようなログが出れば成功です。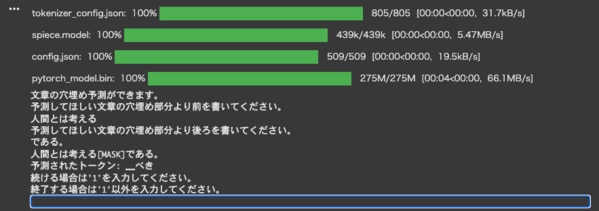
上記のスクリーンショットでは、以下のように入力して結果を得ています。
「予測してほしい文章の穴埋め部分より前」入力内容:
「予測してほしい文章の穴埋め部分より後」入力内容:
結果:
・・・意図した結果ではありませんでしたが、意味は通っています。
より訓練すれば精度は上がりそうですが、現時点でも日本語の意味として矛盾することはあまりありません。
二回目以降の挙動
実行を複数回行うと、キャッシュ等の理由で実行できないことがあります。
以下のコマンドで解決しましょう。
GPU制限時の挙動
なお、GPU制限等でNVIDIAのGPUドライバが見つからない等のエラーが出ることがあります。以下のコマンドを実行し、NVIDIAのGPUドライバがマウントされているか確認できます。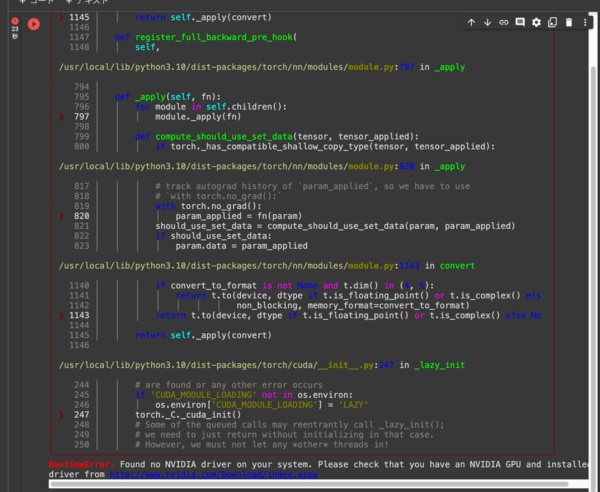
GPUがマウントされている場合: 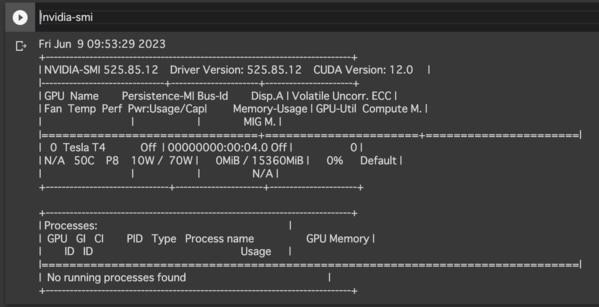
GPUがマウントされていない(NVIDIAのドライバがない)場合: 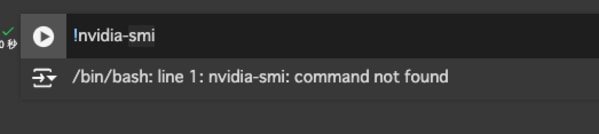
終わりに
今回は無料で使える範囲で、Google Colaboratoryの使い方、Hugging Faceの紹介をしてきました。
コードは複雑ですが、ChatGPTにエラーログを読ませることで実際に動くコードに近づいていきます。
これをきっかけに色々なLLMに触れることで、ファインチューニング等の発展的な学習につなげていただけますと幸いです。



