【Git】Gitのコミットの裏側で何が起きているのか(スナップショットとは何?)
目次[非表示]
- 1.はじめに
- 2.Gitの概要
- 3.何気なく使っているgitコミットはどのように保存されているか
- 4.Gitのスナップショットを使用してのバージョン管理方法
- 5.スナップショットとは何?
- 6.なぜスナップショットとして記録するのか
- 7.コミットされた時のスナップショットの動き
- 7.1.①圧縮ファイルが作られインデックスに追記される(git addコマンド)
- 7.1.1.git addの裏側のイメージ図
- 7.2.②treeオブジェクトが作られる
- 7.3.③commitオブジェクトが作られる
- 8.実際に手を動かしてみた
- 8.1.圧縮ファイル名確認
- 8.2.git addして圧縮ファイルを作成
- 8.3.ツリーファイル(treeオブジェクト)
- 8.4.コミットファイル
- 9.おわりに
はじめに
こんにちは。株式会社divxのエンジニア小柳津です。divxに入社し実務を進める中で、私自身Gitに何度も助けられてきました。ファイルの変更を戻したかったらリセットし、作業している機能毎にコミットするなど自分のローカル環境で自由にファイル管理ができるので安心して開発を進められています。
とても便利なGitのシステムですが使っていて疑問に思うことがありました。何気なくコミットし、元に戻したかったらリセットコマンドで戻すなどコマンド1つでなんでもやってしまう裏側で何が起きているのか?とても気になりました。私は、コミットし変更を戻したりとなんとなくコマンドを打っていました。何となく使うのではなく仕組みから知っていれば今後自分自身、会社メンバー、そして何よりも良い品質のサービスを開発し顧客の幸せに繋がり還元できると思いました。今後もチーム開発で必須ともいえるGitについて記事を書くことで理解を深めていきたいと思います。
Gitの概要
Gitとは、分散型バージョン管理システムです。Gitで管理しているファイルであれば、コンピューター上でファイルの編集履歴を管理できるので、編集前のファイルを残したまま、新しく編集したファイルを保存することができます。なので古いバージョンから新しいバージョンまでの管理が簡単にできます。エンジニアとして開発をしていると、コードを編集し、何か不具合が起きたときに、元のバージョンへ戻すことが多くあります。ひとつひとつコードの編集の度に古いバージョンの日付や時刻ををつけて保存して、また新しい作業をするようなことをしていては、時間はかかり、ミスも増えてしまいます。そういった作業を無駄なく、効率的に行うためのツールがGitです。
Gitを利用することで、開発者間で記述したソースコードの変更履歴を記録する事ができます。Gitでは自分の開発用パソコンに全ての変更履歴を含む完全なフォルダーの複製を作成し、開発者それぞれが自由に変更を加えることができます。Gitは複数人で開発する現場では必須ツールと言えます。
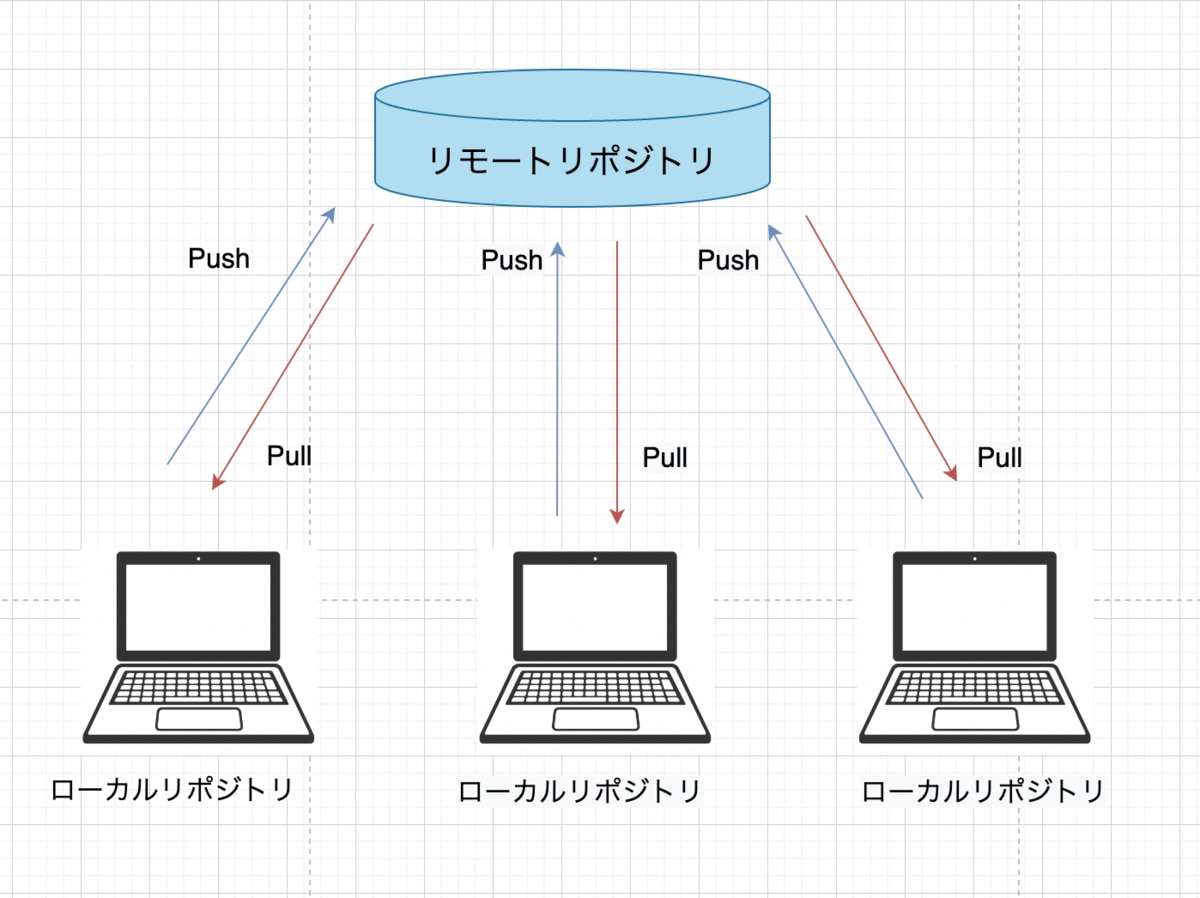
何気なく使っているgitコミットはどのように保存されているか
Gitはスナップショットを記録しています。コミットは、以前のスナップショットに対応する親コミットのリストを持ち、親のないコミットはルートコミットであり、複数の親を持つコミットはマージコミットと言います。コミットには。名前、メールアドレス、日付、およびコミットメッセージといったデータが含まれています。コミットメッセージは、コミットの作成者がそのコミットの目的を説明するためのものです。
Gitと他のバージョン管理ツールとの違いは、データの持ち方です。他のシステムのほとんどは、情報をファイルを基本とした変更のリストとして格納します。これらのシステム(CVS、Subversion、Perforce、Bazaar等々)は、図1に描かれているように、システムが保持しているファイルの集合と、時間を通じてそれぞれのファイルに加えられた変更の情報を保存してるが、Gitは差分ではなくスナップショットで保存しています。
図1
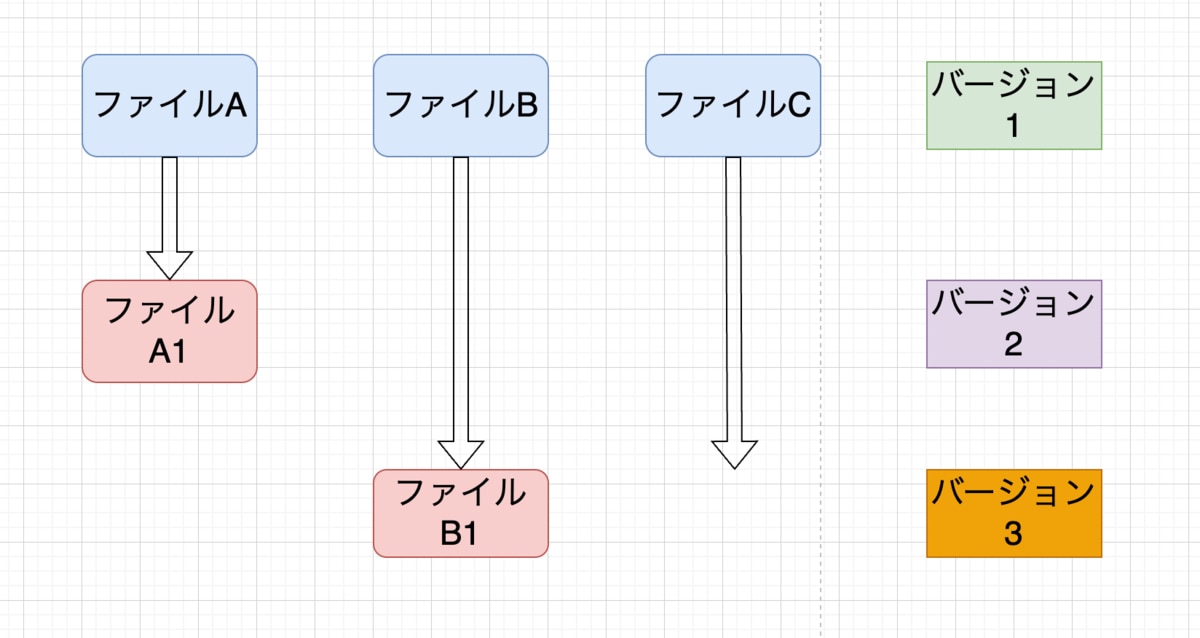
他のシステムは、データをそれぞれのファイルの基本バージョンへの変更として格納する傾向があります。Gitは、この方法ではデータを保存しません。Gitはスナップショットの集合のように保存します。Gitで全てのコミットをするとき、もしくはプロジェクトの状態を保存するとき、Gitは基本的にその時の全てのファイルの状態のスナップショットを撮り、そのスナップショットへの参照を格納するのです。効率化のため、ファイルに変更が無い場合は、Gitはファイルを再格納せず、既に格納してある、以前の同一のファイルを格納します。Gitは、データを一連のスナップショットのように保存しています。
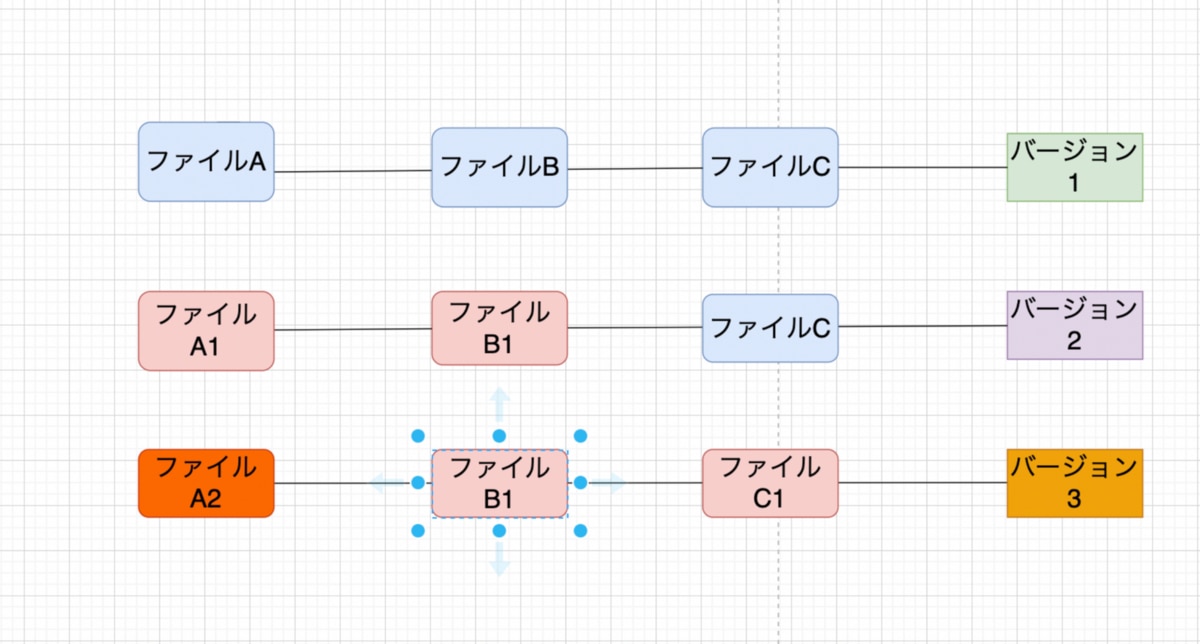
Gitのスナップショットを使用してのバージョン管理方法
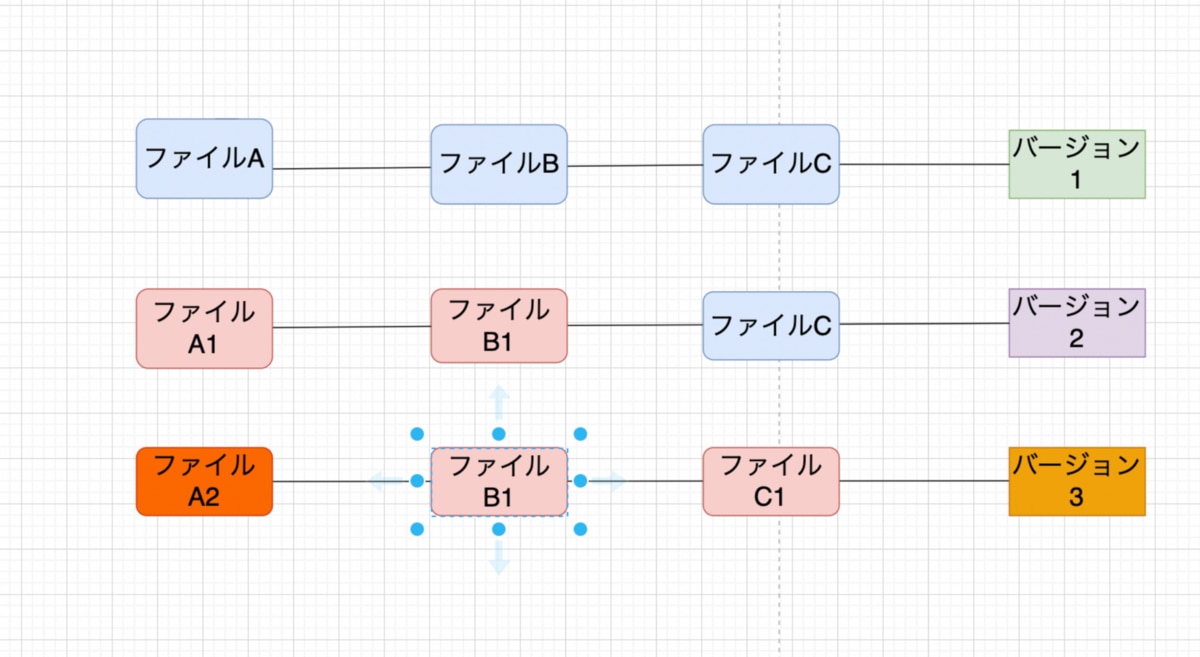
ファイルA、ファイルB、ファイルCという3つのファイルがあったとし、その三つの状態をまずバージョン1として保存します。
次に、ファイルCはそのままで、ファイルAをA1にし、ファイルBをB1に変更します。この時の状態をバージョン2として保存します。ファイルA1とB1は、ファイルA、Bとの差分ではなく、A1、B1をスナップショットとしてファイルを丸ごと保存しています。ファイルCに関しては変更されていないのでバージョン1で保存したデータを使います。こうすることで、バージョン2ではファイルA1、ファイルB1、ファイルCのデータ丸ごとが保存されています。
次に、ファイルA1をA2に、ファイルB1はそのまま、ファイルCをファイルC1に変更します。その状態をバージョン3として保存します。今回はファイルA2とファイルC1は新しく丸ごと保存して、ファイルB1は前回保存した分を使い回します。これでバージョン3が記録されます。このように、Gitはデータをスナップショットとして記録しています。
スナップショットとは何?
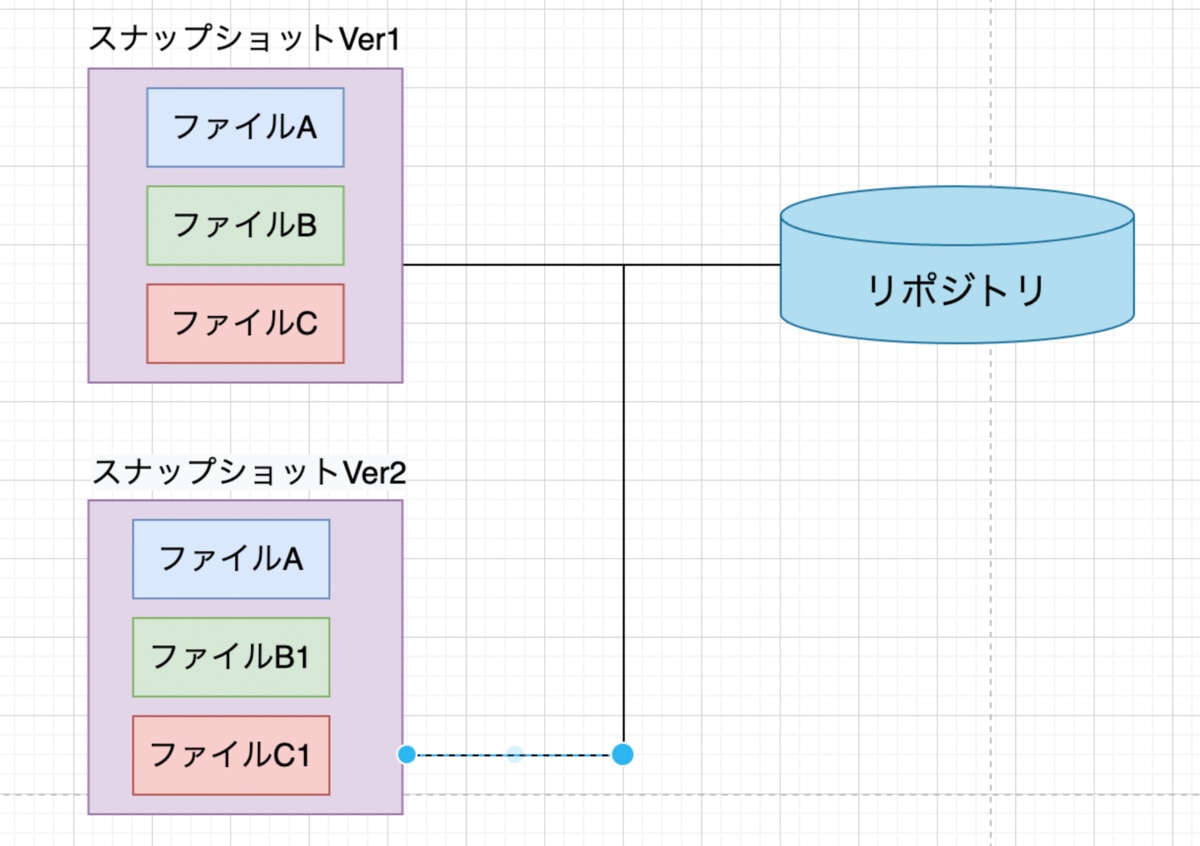
「スナップショット」は、ファイルの変更履歴管理で使用する仕組みです。Gitでは、変更されたファイルをデータベースに保存する際、Gitが管理しているすべてのファイルおよびファイルの情報を記録し、データベースに保存します。スナップショットにより、以前のファイルを取り出したり変更点を調べるなど、過去の作業を抽出できるようになります。変更されたファイルの内容全体を保存し、前のデータとの差分を保存しているわけではないのです。
なぜスナップショットとして記録するのか
スナップショットとして記録することで、複数人で開発する時のスピードを上げることができます。複数人での開発の際、並行して開発できるよう、Gitではブランチというものを切って、バージョンを枝分かれさせて開発していきます。このブランチでバージョンを枝分かれさせる際や、ブランチを統合(マージ)する際にスナップショットだと非常に作業が速くできます。
Gitがデータを差分というかたちで持っていると、ブランチを切ってマージする時に差分をいちいち計算しなければなりません。しかしスナップショットで保存しておけば、差分の計算をしなくて済む分、とても速くブランチを切ったりマージできるようになります。
コミットされた時のスナップショットの動き
①圧縮ファイルが作られインデックスに追記される(git addコマンド)
ファイルの変更をステージにのせるためgit addコマンドを実行すると、ステージにのせたファイルを圧縮したファイルが.git/objects以下に保存されます。以下コマンドで圧縮ファイルの中身を確認できます。
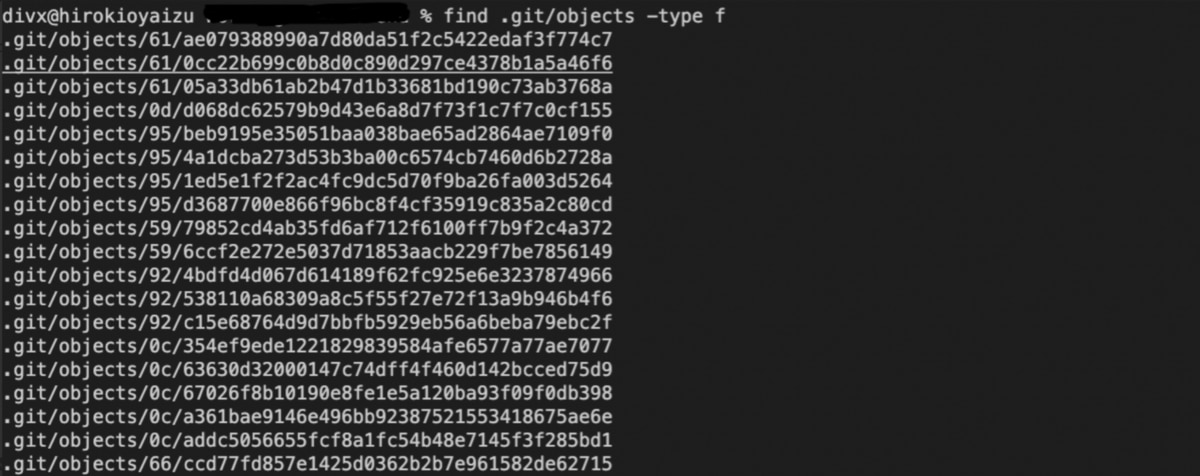
追加されたファイルはblobオブジェクトと呼ばれ、ファイルの内容を圧縮したものになります。objectsディレクトリの中にファイルがあり、SHA-1(SHA-2も使う事は可能)でハッシュ化しblobオブジェクトのIDが作成されます。SHA-1ハッシュのはじめの2文字がサブディレクトリの名前になり、残りの38文字がblobオブジェクトのファイル名の形式で格納されます。
この時blobにはファイル名の情報は含まれていません。どうやってファイルの構造と名前を保持するのかというとそれがインデックスです。git addコマンドを実行すると、blobオブジェクトが作成された後、インデックスに追記されます。インデックスは、.git/indexというバイナリファイルで管理されています。プロジェクトのある時点でのディレクトリツリー全体を表すデータを持ちます。
インデックスの中身を見る方法は、git ls-files –stageコマンドで.git/indexの内容を見ることができます。

左からパーミッション、blobオブジェクトのID、ステージ、ファイルパスが表示されます。git addした時点でのblobオブジェクトのIDとファイルパスを紐付けて管理することで、ディレクトリーツリーの情報を保存します。
git addの裏側のイメージ図
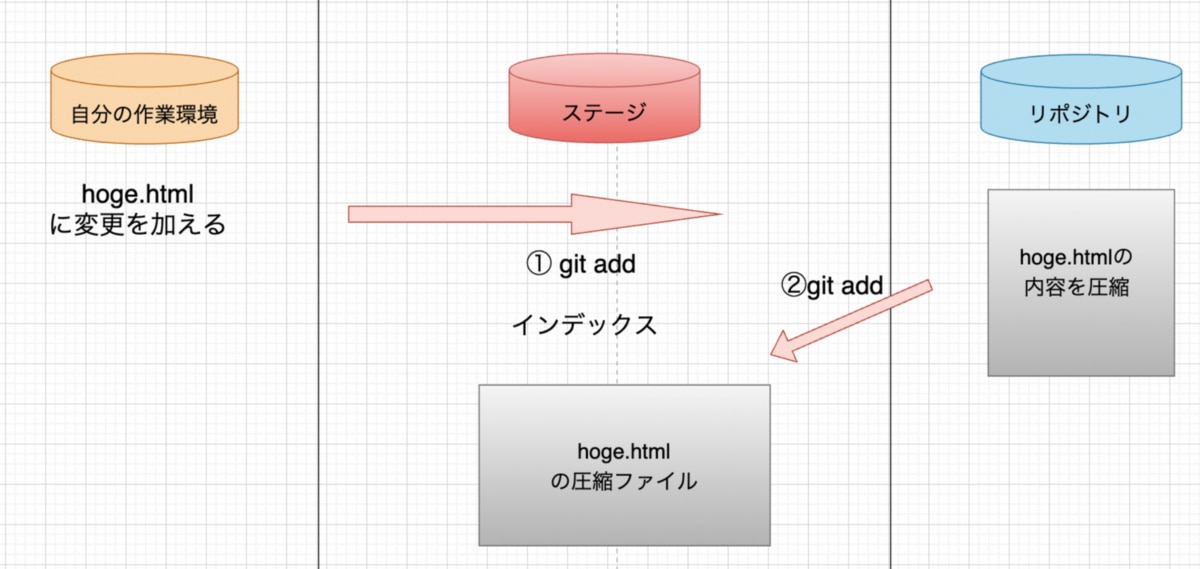
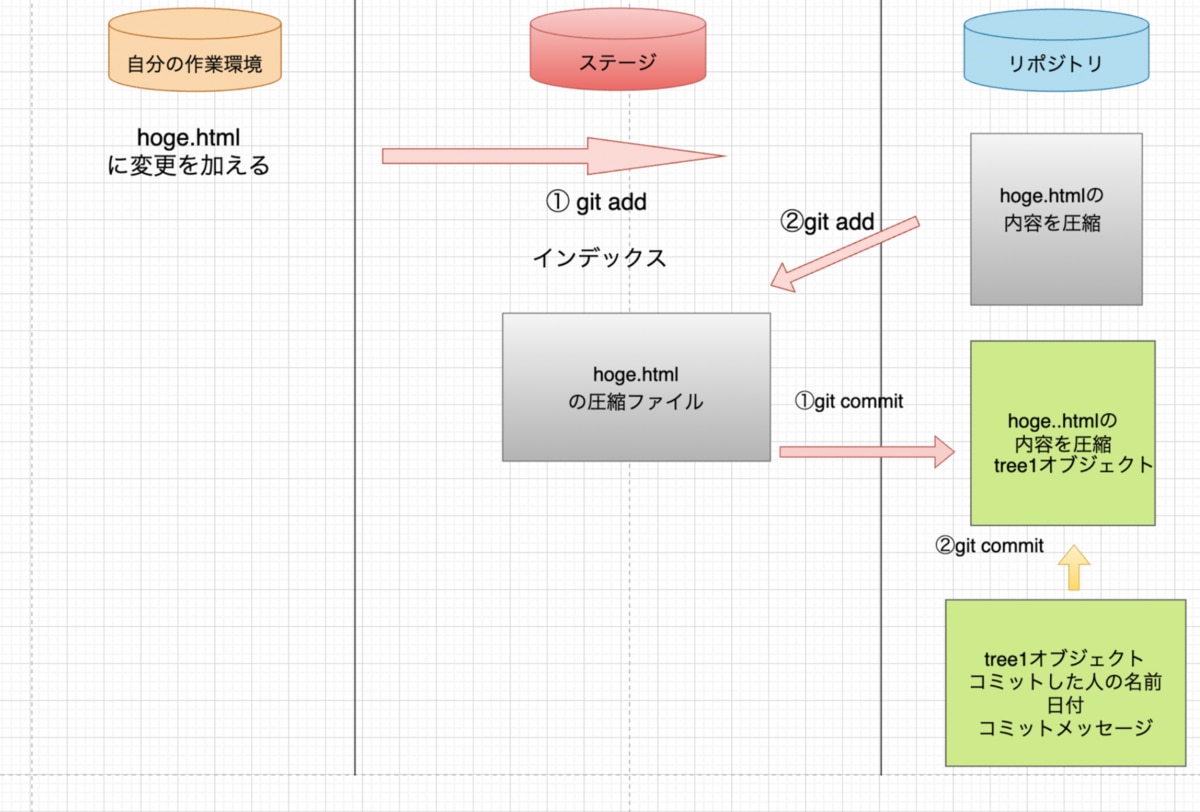
「hoge.html」というファイルを新しく作ったと想定し、git addコマンドでファイルをステージに追加し、圧縮ファイルが作られインデックスに追記されるまでの動きを見てみます。
ステージに追加する時はまず「hoge.html」のファイルの中身を圧縮した圧縮ファイルをリポジトリに保存します。圧縮ファイルと書いてますが上に書いた通り実際はファイルの中身にヘッダーを付け加えた文字列をハッシュ関数で暗号化した文字列がファイル名になります。
圧縮ファイルができたら、今度はインデックスというファイルにhoge.htmlのファイル名とファイルの中身を紐付けた情報を保存して行きます。ファイルの中身をまず圧縮して、インデックスのhoge.htmlに情報を記載すると言うのがステージに追加する時に裏側で起こっていることです。これを実行しているのが「git add」コマンドです。
②treeオブジェクトが作られる
git commitコマンドを実行するとまず、treeオブジェクトが.git/objects以下に保存されます。
treeオブジェクトはファイル構成を表すファイルを作成します。ファイル名とファイルの中身の組み合わせを保存するためにあるのがツリーファイルです。コミットをするとツリーファイルが作成され、ツリーファイルは「treeオブジェクト」と言います。treeオブジェクトもインデックスと同じように、オブジェクトのIDとファイルパスを紐付けることで、ディレクトリーツリーを保持するためのものになります。コミットすると、そのたびにtreeオブジェクトとcommitオブジェクトが作成され、その時点でのディレクトリーツリーが毎回保存されます。そうすることでGitは変更履歴を保存しているのです。それに対してインデックスは、インデックスした時点で.git/indexを毎回上書します。あくまでインデックスは、変更をまとめてコミットするための準備をする場所です。インデックスすると.git/indexにディレクトリーツリーが上書きされ、コミットするとその時点での.git/indexの情報を元にtreeオブジェクトが作成されます。
③commitオブジェクトが作られる
treeオブジェクトのおかげでコミット時のディレクトリーツリーが分かるようになりました。ここでついにコミットすることで誰が、いつ、何のために変更したのかという情報が保持することができます。コミットすると、treeオブジェクトが作成された後に、.git/objects以下にcommitオブジェクトが作成されます。
commitオブジェクトの中身は、直前のコミット、作成者とコミッターの情報、空行、コミットメッセージです。(こちらの中身は後ほど紹介します)ツリーを保存することでコミットした時点のスナップショットが、作成者とコミッターの情報からいつ誰が、コミットメッセージからなぜ、どのような変更をしたのかということがわかるようになっています。
Gitはcommitオブジェクトにtreeオブジェクトを保持することで、その時点でのスナップショットがわかるようにしています。加えて、直前のコミットを親コミットとして保持しておくことで、コミットの履歴を辿れるようにしているわけです。これがGitのバージョン管理の仕組みです。
実際に手を動かしてみた
圧縮ファイル名確認
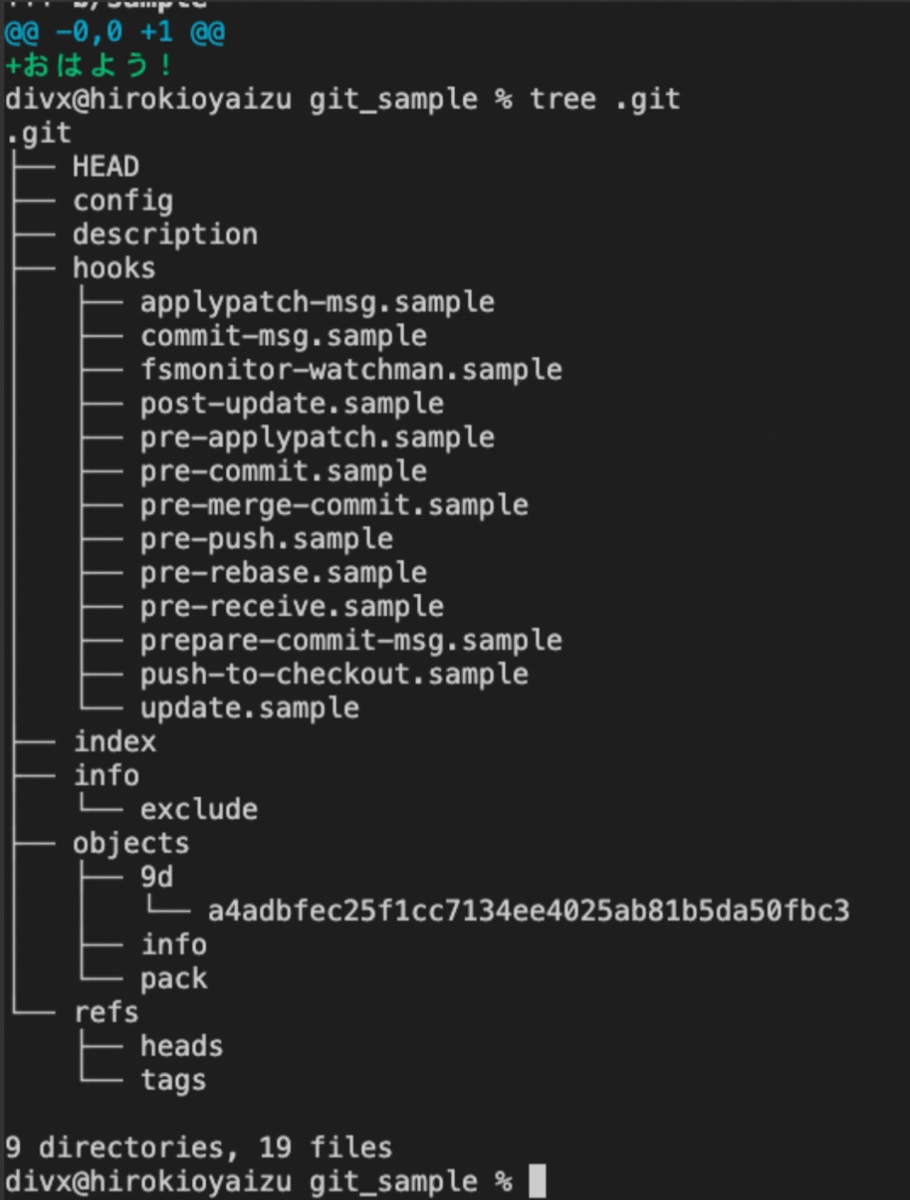
圧縮ファイル名は40文字の英数字と上記に説明しました。本当にそのように表示されるのかaddして確認してみたいと思います。

git addして圧縮ファイルを作成
圧縮ファイルは「.git/objects/9d/a4adbfec25f1cc7134ee4025ab81b5da50fbc3」になっています。先頭2文字をディレクトリ名、残り38文字をファイル名として保存していることを確認できました。
ハッシュIDとは、ファイルの中身に対して計算される固定長の文字列です。ファイルの中身に変更があればgit addすると別の英数字(ファイル名)が作成され、同じなら作成されません。
試しにファイルの中身に追記をしてaddをすると英数字(ファイル名)はどうなるでしょうか?
前回のaddしたsampleファイルのハッシュID「9da4adbfec25f1cc7134ee4025ab81b5da50fbc3」とは別のハッシュIDが作成されています。
ツリーファイル(treeオブジェクト)
ファイル構造を保存するためにあるのがツリーファイルです。コミットをするとツリーファイルが作成されます。ディレクトリの一つの階層ごとに1つのツリーファイルになっていて、ツリーファイルには圧縮ファイルだけでなくツリーファイルも保存されています。Gitオブジェクトの中身を確認するにはgit cat-file -p <確認したいオブジェクト>で確認できます。
(公式ドキュメントのコマンドを参照)
https://git-scm.com/docs/gitrevisions#_specifying_revisions
「9da4adbfec25f1cc7134ee4025ab81b5da50fbc3」がsampleというファイル名で保存されています。これが最後のコミットが指しているtreeの、blobオブジェクトです。
ファイルではなくディレクトリ追加するとどのように管理されるのでしょうか?ディレクトリを追加してコミットしてみます。
ディレクトリ追加してみると、ツリーファイルの中にツリーファイルが含まれてます。ツリーファイルは1つのディレクトリに対応していて、ツリーファイルの中にツリーファイルと圧縮ファイルが含まれるように管理されてるのですね。
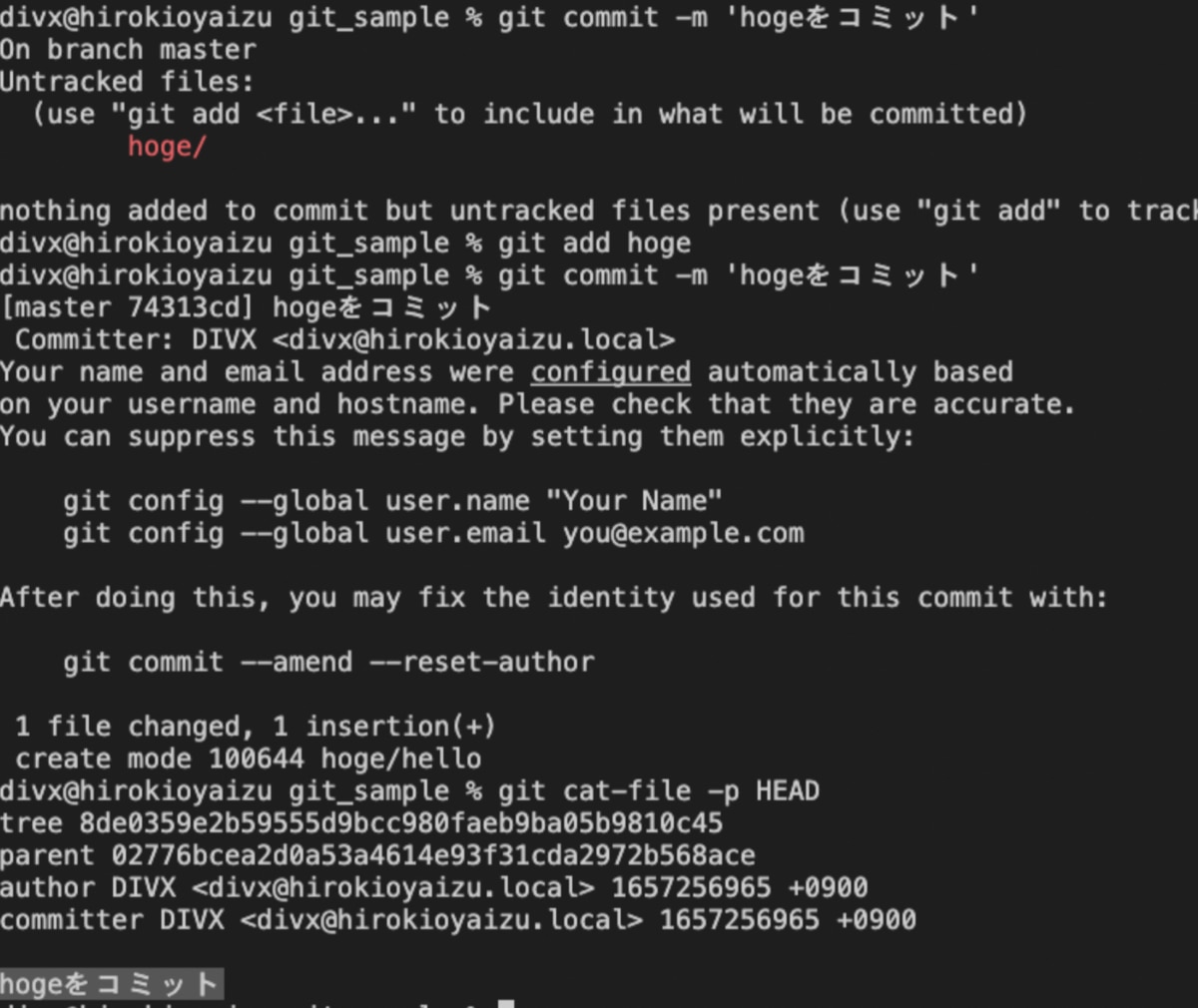
hogeのツリーファイルの中身も確認してみます。
hogeディレクトリにはblobオブジェクト「b01625111fe65030fd322e875eaa3d2fbdea83b7」がhelloというファイル名で保存されています。
1つのディレクトリに1つのツリーファイルが対応し、1つのファイルに1つの圧縮ファイルが対応していることがわかります。
コミットファイル
いつ、誰が、何を、何のために変更したのかということをまだ保存できていません。
その情報を保存するためにあるのがコミットファイルです。コミットファイルは「commitオブジェクト」と言います。
コミットファイルの中身を確認してみます。
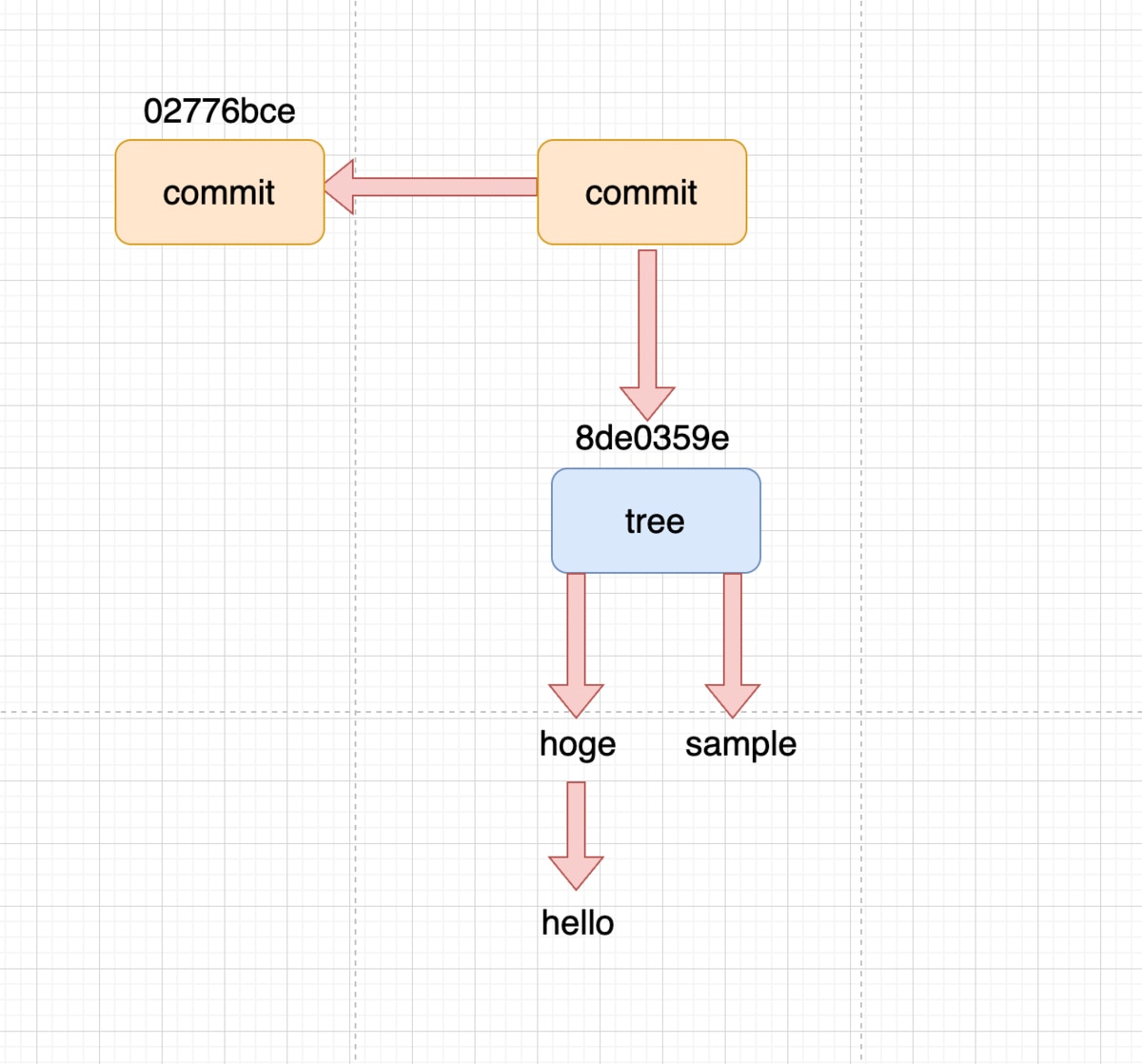
コミットしたtree
「8de0359e2b59555d9bcc980faeb9ba05b9810c45」が保存されています。1番上の階層のツリーをコミットファイルに保存することで、コミットした時点でのスナップショットを記録しています。
parentの「02776bcea2d0a53a4614e93f31cda2972b568ace」は親コミットを保存しています。Gitはこのように親コミットを保存することでコミットの履歴を辿れるようにしてます。authorは作成者の名前とメールアドレスが記され、一番下の「hogeをコミット」がコミットメッセージです。
おわりに
私はGitを何となく使用しコミットやリセットをしていました。今回記事を書くことでGitの裏側の動きを深く知ることができました。
gitのローカルリポジトリに保存される仕組みは、blobオブジェクト、treeオブジェクト、commitオブジェクトの3つおかげでした。ファイルの中身の管理は、blobオブジェクトが管理し、ディレクトリやファイルの構成の管理はtreeオブジェクトが管理し、いつのバージョンのデータなのかわかるように管理してくれてるのはcommmitオブジェクトでした。
データをスナップショットとして保存していることで差分の計算をしなくて済む分、とても速くブランチを切ったりマージできるようになります。別のバージョン管理ツール同様にデータを差分というかたちで保存していたら、ブランチを切ってマージする時に差分をいちいち計算しなけれ大変時間がかかっていたと思うのでGitのシステムに改めて感謝したいなという気持ちになりました。
今回この記事を書きこの知識を他のメンバーにも還元しつつ、お客様により良いサービスを提供しチームメンバーと開発していこうと思いました。
最後までお読みいただきまして、ありがとうございました。
divxでは一緒に働ける仲間を募集しています。
興味があるかたはぜひ採用ページを御覧ください。